
 LinkedIn
LinkedIn
This is the fourth post in our Databricks GenAI series. If you have read the previous posts, we have setup Databricks to play chess, and we found that Large Language Models are not good at playing chess. Further, we examined that there is still evidence of hallucination despite all the facts are given, if not all the facts are considered properly it could lead to serious business “blunders”. In this blog post, we want to examine some fine-tuning techniques provided by Databricks. We will reference the work from the paper “ChessGPT: Bridging Policy Learning and Language Modeling” by Xidong Feng, et. al. (NeurIPS 2023)

Before diving into the fine-tuning API, let’s have a look at an early form of reasoning models, which is arguably one of the easiest ways to explain how reasoning models work. There are two components presented in the paper, one is our favorite large language model, another is policy learning. The following 3 points explains why “reasoning models” are as a result of “Bridging Policy Learning and Language Modeling”:
- Language Modeling (LM) Component
a) LLMs generate text by performing next-token prediction.
b) Advances like Chain-of-Thought (CoT), Tree-of-Thought (ToT), and self-consistency enhance multi-step reasoning beyond just text generation. - Policy Learning Component (Reinforcement learning)
a) Modern agentic AI systems (e.g., ReAct, LangGraph-based agents, DSPy-based agents, e.g. our chess-playing agent) require structured decision-making (e.g. nodes and edges).
b) Models use reinforcement learning (RLHF), search-based planning (e.g., Monte Carlo — think AlphaZero), and tool use (aka function calling) — are a kind of reinforcement learning (aka policy learning principles). - Reasoning Models as the Bridge
a) Reasoning models don’t just generate words; they decide on intermediate reasoning steps and refine outputs.
b) Open-weight models and tool-augmented architectures reinforce structured, decision-based reasoning.
c) The growing autonomy in AI agents (e.g., auto-planning, adaptive workflows) demonstrates policy learning elements embedded within LLMs.
Databricks Fine-tuning API
According to the ChessGPT paper, “Human decision-making typically involves both: we draw upon historical policy interaction to refine our policy and also employ our thoughts for strategic consideration, mostly in natural language form.” We know that from experiment and the fact that LLMs are not good at playing chess due to these two forms of data are rarely coupled together for learning. The advanced reasoning skills is beyond the capability of prompt engineering or retrieval augmented generation (RAG). That’s why it makes sense to provide specific data to a model and do a fine-tuning. There are two ways to access Databricks’ fine-tuning API, one is through the databricks python package:
from databricks.model_training import foundation_model as fm
|
Another is via the UI, which can be found in the Experiments tab.
There are three fine-tuning tasks available on Databricks:
- Chat Completion
- Continued Pre-training
- Instruction Fine-tuning
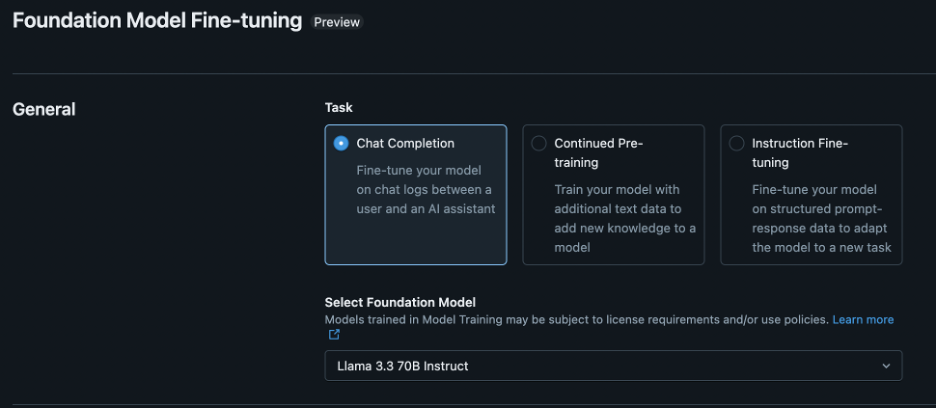
Taking a real-world example, we can learn about how ChessGPT paper is leveraging these 3 fine-tuning methods to create a large language model called ChessGPT.
1. Chat Completion:
The authors developed ChessGPT-Chat, which is a chat model created by conducting supervised fine-tuning on conversation response data by leveraging conversational data from chess forums as well as responses from various LLMs.
2. Continued Pre-training:
For continued pre-training, the authors fine-tuned a base model using a large corpus of chess-related data including game dataset(e.g. lichess dataset), language dataset (e.g. chess blogs) and mixed game-language dataset (e.g. YouTube transcripts). While they chose to fine-tune the RedPajama-3B-base model due to computational constraints, Databricks fine-tuning API allows users to tune on the Llama family models and the best news is that everything is serverless.
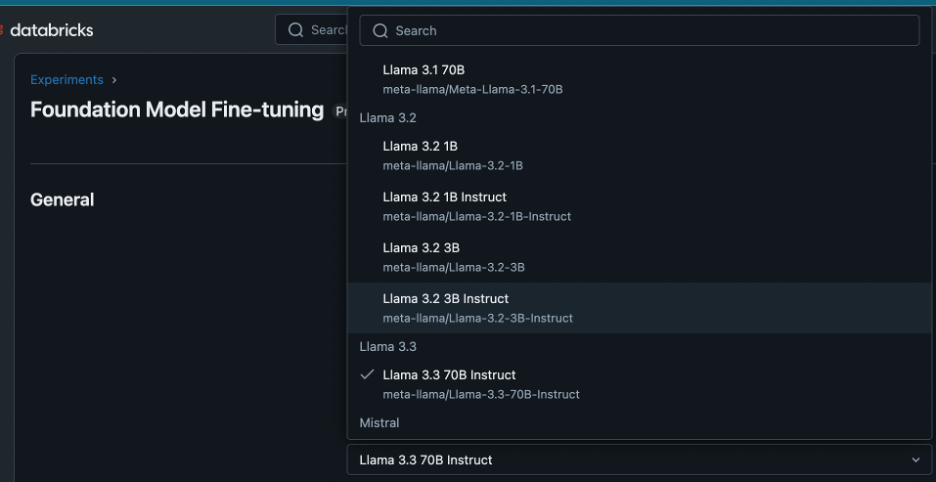
3. Instruction Fine-tuning:
Inspired by Alpaca, the authors utilized the self-instruct technique to generate high-quality, instruction-following data through GPT-4. They manually constructed seed prompts for chess-related questions or instructions, which served as few-shot examples to guide GPT-4 in generating coherent and relevant responses.
For example:
- What is it called when a player can’t defend an attack against their king? (Answer: checkmate)
- e4 e5 2.f4, What is the name of this opening? (Answer: King’s Gambit)
Conclusion
Fine-tuning used to be some advanced techniques available only to top-notch researchers because of the requirements in deep understanding of the structure of the large language model as well as the technique to clean the data for the model training purposes.
With Databricks Agent Tracing as input data for Fine-tuning API, we can very easily get started with the ChatCompletion task. As we get more familiar with fine-tuning, we can eventually create our own reasoning model similar to ChessGPT. With Databricks Fine-tuning API, we can easily deploy a fine-tuned model to Unity Catalog and as a serving endpoint, ready for the next round of chess with our chess agent!

In the next post, we will attempt to leverage some of the data curated by ChessGPT team and run through a ChatComplete experiment.


