
 LinkedIn
LinkedIn
What is Databricks Asset Bundle (DAB)
It has always been high demand to have an efficient process to deploy databricks workflows, notebooks and other assets from one workspace to another workspace (DEV to QA, QA to Prod etc.).
Databricks Asset Bundles is an out-of-the box offering provided by Databricks for streamlining the development and deployment process of complex data, analytics, and ML projects for the Databricks platform. We can think of Databricks Bundle as a metadata of entire databricks codebase and project including all the assets like note, workflows, clusters etc. This works as an Infrastructure-as-a-Code approach to managing the databricks project. Bundles make it easy to manage complex projects deployment process by providing CI/CD capabilities in software development workflow with a single concise and declarative YAML syntax.
Here we will discuss how to enable and use databricks assent step by step. We will need a deployment engine like Github Action Workflow or Azure Devops or similar platform to perform the deployment tasks.
The diagram below depicts the process flow of CI/CD with Databricks Asset Bundle.

As we can see in this diagram, developers work on a DAB enabled repository (GitHub, Gitlab, ADO etc.) from local development environment. Here, they can develop the application code for data ingestion/transformation, machine learning models etc. along with bundle deployment pipeline configuration.
From the local environment, they can also deploy objects to the Dev workspace to verify and validate the configuration of the whole project deployment and perform test deployment using command line bundle commands. Upon all successful deployment, the pull request and merge process will trigger the CI/CD pipeline that eventually executes bundle commands pointing to specified target workspace environment. This enables a seamless development and deployment of databricks projects.
Databricks Asset Bundle Implementation Methodology
Enabling Databricks Asset Bundle is easy and straight forward process. Here are the high-level steps.
i. Configure Databricks CLI with Databricks Asset Bundle
ii. Setup Databricks authentication
iii. Configure the Databricks Asset Bundles YAML configuration file.
iv. Test Databricks Asset Bundles Configuration
v. Configure CI/CD Pipelines
vi. Deploy Databricks Asset Bundles & Validate
Implementation Process:
We shall discuss the above-mentioned steps in detail step-by-step with examples and references for easy understanding.
i. Configure Databricks CLI with Databricks Asset Bundle: We should install Databricks CLI and Databricks Asset Bundle packages in the local desktop machine where the develop will do the development.
Windows Machine: Run the command below in command prompt with an administrator or required privileged account.
winget install Databricks.DatabricksCLI
Mac Laptops: Run the command below command prompt with administrator or required privileged account.
brew tap databricks/tap
brew install databricks
The above command will install Databricks CLI in the local desktop. Verify the installation by running below command.
databricks version
It should show the latest version that is installed.
If DatabricksCLI is already installed in a machine, we can upgrade that using below commands:
Windows Machine: Run the command below in command prompt with administrator or required privileged account.
winget upgrade Databricks.DatabricksCLI
Mac Laptops: Run the command below command prompt with administrator or required privileged account.
brew upgrade databricks/tap
ii. Set up Databricks authentication: As a next step we need to setup authentication with target databricks workspace. There are many ways to establish authentication, however we will use Personal access token method here for testing. In Ideal scenario, here should be a Databricks service account whose PAT to be used. The PAT token should be generated and kept in Github secret. The below steps to be followed.
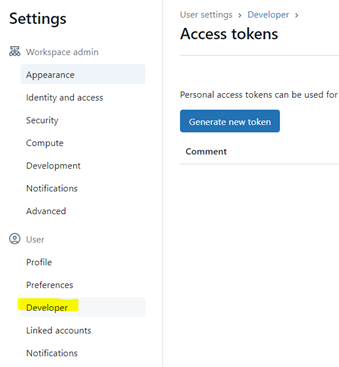
a. Generate the personal access token (PAT) from Databricks workspace settings. Click on the “Generate new token” button, enter a expiry date and token name to generate the PAT and keep it copied somewhere else.
b. Configure databricks local profile from user desktop/laptop: Run the below command in windows command prompt
databricks configure — profile DEFAULT
This command will prompt for databricks workspace URL and the token we created in previous step. Once entered, it will update them .databrickscfg file in your personal user directory or current working directory. We can provide a custom profile name as well instead o DEFAULT.

iii. Configure Databricks Asset Bundle YAML configuration file: This is the core development work in Databricks Asset Bundle. In a DAB project, this can be created by databricks asset bundle init command or manually created, we will have a databricks.yml file which contains the entire configuration metadata of the Databricks project including all artifacts e.g., notebooks, source files, workflows, ML models etc.
Here in this example, we will work with Databricks workflows and basic common settings in the yaml file. This yaml file can be complex based on the actual need and configuration complexity.
Here I will demonstrate various sections of the databricks.yml file with section wise screenshots.
First let’s look at the wholistic content of the databricks.yml content.

As we can see, the initial sections in this Yaml file are simple and there is nothing specific to explain.
So, let’s start exploding the complex sections — job_clusters and target environments (marked blue`)
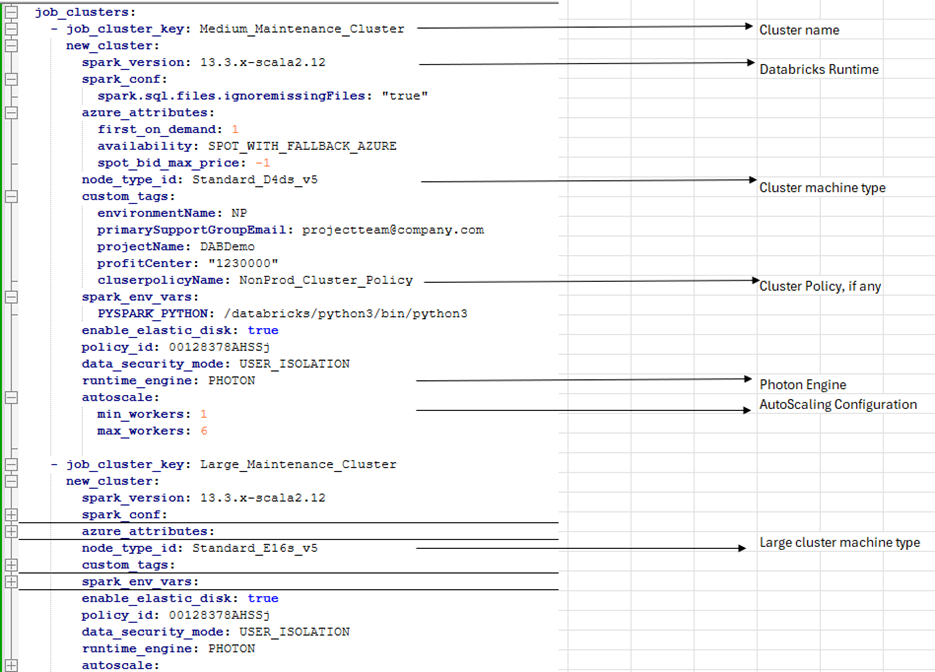
In the above picture, we have defined two clusters of medium and large size with two different machine time and autoscaling parameters.
Next, we are defining the non-prod target environment configurations and deploying the databricks workflows configuration.
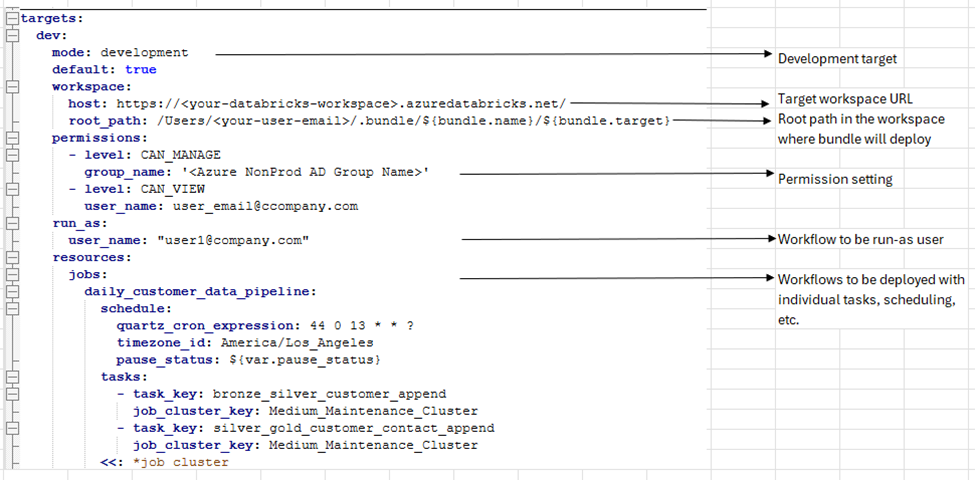
Next, we define the production target deployment environment. Here we override the variable values for prod environment as needed for those variables which we declared at the beginning of the databricks.yml file.
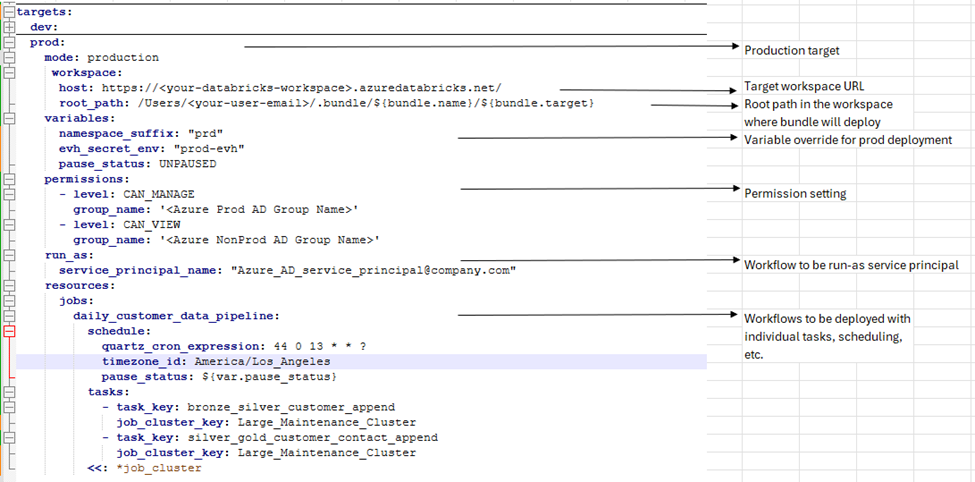
Use this website to generate or validate the quartz cron schedule expression for databricks workflow scheduling — https://crontab.cronhub.io/.
iv. Test Databricks Asset Bundles Configuration: Idea is every developer will be able to test and execute the bundle configuration before the deployment. This databricks.yml is part of the whole project and version controlled in the GIT Repo or ADO or anything similar.
To test the bundle configuration, developer has already configured databricks CLI as discussed above.
So, they need to run a test executing the below command from project directory where databricks.yml is present, ideally in a tool like VSCode.
This command validates the databricks.yml configuration and throws any potential errors.
databricks bundle validate -t “<target env name>” — target env name is as given in databricks.yml file, in our case dev and prod.
Developer can also do a test deployment with the below command
databricks bundle deploy -t “<target env name>”
v. Configure CI/CD Pipelines: As a next step to perform the deployment as a automated CI/CD process, we need to configure the CI/CD pipelines as Github Action workflow or Azure Devops Pipelines. In this demp I have used GitHub Action workflows to run the Devops process.
Here is the snippet of the Github Action workflow.

vi. Deploy Databricks Asset Bundles & Validate: Run the GitHub Action workflow on commit to a feature branch or PR push to main branch or upon creating a production release tag. Then every time the triggering event occurs this Github action pipeline will perform an automated DAB deployment to deploy all databricks assets to a higher environment workspace precisely.
From CI/CD automation to scalable data platforms, see how organizations modernize their Databricks environments
Transition of an existing Databricks project to Asset Bundle Project:
Let us discuss how we need to enable databricks asset bundle in an existing project. Assuming the existing project is in a version-controlled repository like Github or Azure Devops or something similar, we need to create a fresh new repository for asset bundle and transfer existing code there. This could be a moderately complex and time-consuming effort but one-time investment to implement asset bundle will go a long way in future. Based on the complexity of each individual project the steps to enable asset bundle can be tweaked but baseline steps as mentioned below would follow.
1. Create a new repository — Create a fresh new repository in the platform of choice (GitHub, Gitlab, ADO etc.) and clone into VS Code locally
2. Follow the first three steps of “Implementation process” section of this article, this will create a skeleton of asset bundle project with databricks.yml.
The bundle project structure should look like this (GitHub example)
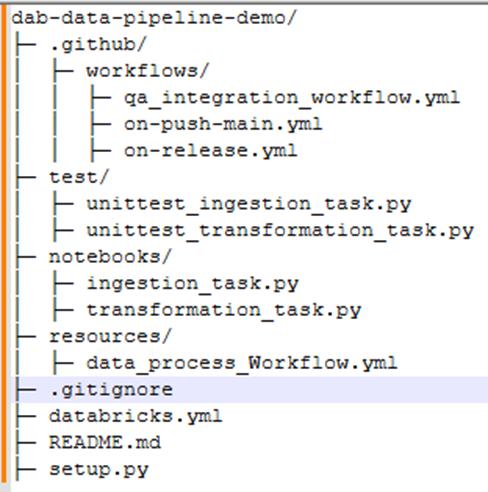
3. Move existing notebooks (pySpark, DLT etc.) into the new repository notebook directory
4. Define existing workflows as yaml file into the resource directory. This can be easily doable to extracting the yml from existing databricks workflows
5. Develop the github action workflow or Azure pipelines as yml files based on the CI/CD strategy. A few samples are shown above.
Once this is completed, we need to run the github action workflow to deploy the bundle which will create all assets (notebooks, init-scripts, workflows, SQL queries etc.) into the databricks workspaces.
Then the development team will use this repository to continue their usual software development life cycle.
Common errors and mitigation of bundle deployment and validation:
We might encounter various errors during bundle validation and deployment. Bundle validation typically checks the yml file syntax, resources, integrity of the bundle project structures, variables etc.
Any issues with these will throw errors during validation. After bundle validation passes, we can still get runtime errors during bundle deployment and deployment will fail. Here I will discuss a few common errors I faced if that helps.
1. Yaml file syntax error — Yaml file is highly sensitive to its syntax. Extra space or comma or any misplaced character will cause syntax issues during bundle validation
2. Wrong attribute in Yaml File — Often we may use wrong or incompatible attributes in the databricks.yml file or workflow Yaml files that lead to bundle validation errors. It could be difficult to find the right attribute based on the need. We can run the command below to get the whole dictionary of asset bundle attributes which can be used. This is an exhaustive list, which can be used as a good reference guide to implement complex bundle configurations.
3. Inappropriate usage of variables and hard coding: Using variables in DAB deployment is very advantageous but incorrect usage of variables (missing declarations, missing default values, duplicate variables etc.) could be causing validation issues. Environment specific variable value overrides could also be very critical (example shown in prod deployment target section above). Also using {bundle.target} variable to replace target environment name in code and configuration is very required instead of hardcoding the environment name.
4. Cluster Error: We can encounter cluster provisioning errors during deployment run because of missing custom tag names, or incorrect cluster policy values given in the databricks.yml file which prevents to assign or provision the cluster during deployment.
5. Permission Error: The deployment agent should have required permission to deploy the assets to the databricks workspaces. Also the permission settings in the databricks.yml should be accurate with correct parameters and AD/IAM group names.
Customer Success Story:
We have implemented Databricks Asset Bundle for a retailer giant based out of North America for their central data management platform implementation.
Context: Previously they used to have databricks notebooks for their ingestion and transformation tasks. Those databricks notebooks are triggered and orchestrated by Azure Data Factory (ADF) pipelines. The entire framework was quite a bit of complex architecture running on Azure Function App for time-based triggering, Azure Data Factory for orchestrating and invoking databricks notebooks, Azure Service Bus for messaging with Function App. It was a manual, fragmented and error-prone process resulting in 20–30% more engineering effort during release cycle.
Solution: With the release of Databricks Asset Bundle feature by Databricks, we took this as an opportunity to modernize and simplify this job execution process. We programmatically created 1500+ Databricks workflows with the associated notebooks and notebook level parametrization. The whole codebase is integrated into a GitHub repository. With the asset bundle, we created the bundle deployment methodology to deploy all the workflows with underlying notebooks, parameters, schedules, notification, cluster configurations etc. seamlessly to higher environment. Consequently, we decommissioned all the Azure native services simplifying the whole process and architecture and most importantly saved a lot of cost.
Asset Bundles drastically simplify and standardize the way we manage and deploy Databricks resources. With a single declarative YAML spec and CLI commands, teams can now version, test, and promote their assets across dev, staging, and prod environments — cutting deployment effort by up to 50%.
Direct Benefit and ROI of asset bundle implementation:
1) Simplified architecture only on Databricks platform
2) Retired native Azure services
3) Seamless and fast development and deployment cycles
4) Direct cost savings of the Azure services
5) Faster onboarding of new workflows

Conclusion:
Before the introduction of Databricks Asset Bundles, managing and migrating Databricks assets — such as notebooks, workflows, init scripts, MLFlows, and queries — across environments was a fragmented and complex process. Many organizations relied on external orchestration tools like Azure Data Factory (ADF) to trigger and manage these assets, leading to inefficiencies, increased engineering effort, and higher operational costs.
With the adoption of Databricks Asset Bundles, we have transformed this process into a streamlined, efficient, and standardized workflow, which has delivered significant value to our client, including direct cost savings, improved operational efficiency, and enhanced scalability. The ability to maintain multiple bundles within the same workspace for different projects or lines of business further underscores the flexibility and power of this solution.
In summary, Databricks Asset Bundles is a game-changing feature that simplifies data engineering and operational workflows, enabling organizations to focus on innovation rather than infrastructure complexity. It’s a testament to how modern tools can drive efficiency, reduce costs, and future-proof data platforms.
Reference: https://docs.databricks.com/aws/en/dev-tools/bundles/

