


The world of data science, machine learning, and artificial intelligence is rapidly evolving, and cutting-edge Language Models (LLMs) and Generative AI (GenAI) are driving innovation across industries. Achieving competency in these sophisticated fields often involves navigating a complex web of tools and frameworks. The need of the hour for big organizations essentially boils down to the following: -
- Single Source of Truth for Data with Security
- Centralized Insight Generating System with Access Control
- Cross-Functional Insight Delivery Mechanism
The above pointers highlight the need for a robust data infrastructure that ensures data accuracy, security, accessibility, and utilization across an organization, empowering informed decision-making at various levels and hierarchies.
Some Fortune 100 companies and retail/CPG giants have taken initiatives to develop internal Data Science (DS) Framework(s) and tools that integrate with the organization’s data, provide the platform to build and version the models/insights and deploy them. However, the seamless integration with the backend data and maintenance of versioning/registry of diverse ML/LLM models has always been a bottleneck. We will explore how Databricks and MLflow, in conjunction with internal tools and data science frameworks, can dramatically accelerate your expertise in LLM and GenAI use cases, providing real-world examples to illustrate their integration.
What is MLFlow
MLFlow is an open source platform machine learning lifecycle management. MLflow has become widely embraced as an open-source project, with Databricks emerging as a major driving force behind its success. While the community's diverse contributions play a crucial role, Databricks, as the primary contributor, underscores the significant impact industry leaders can have in advancing collaborative, open-source initiatives within the machine learning landscape. Click here to learn more.
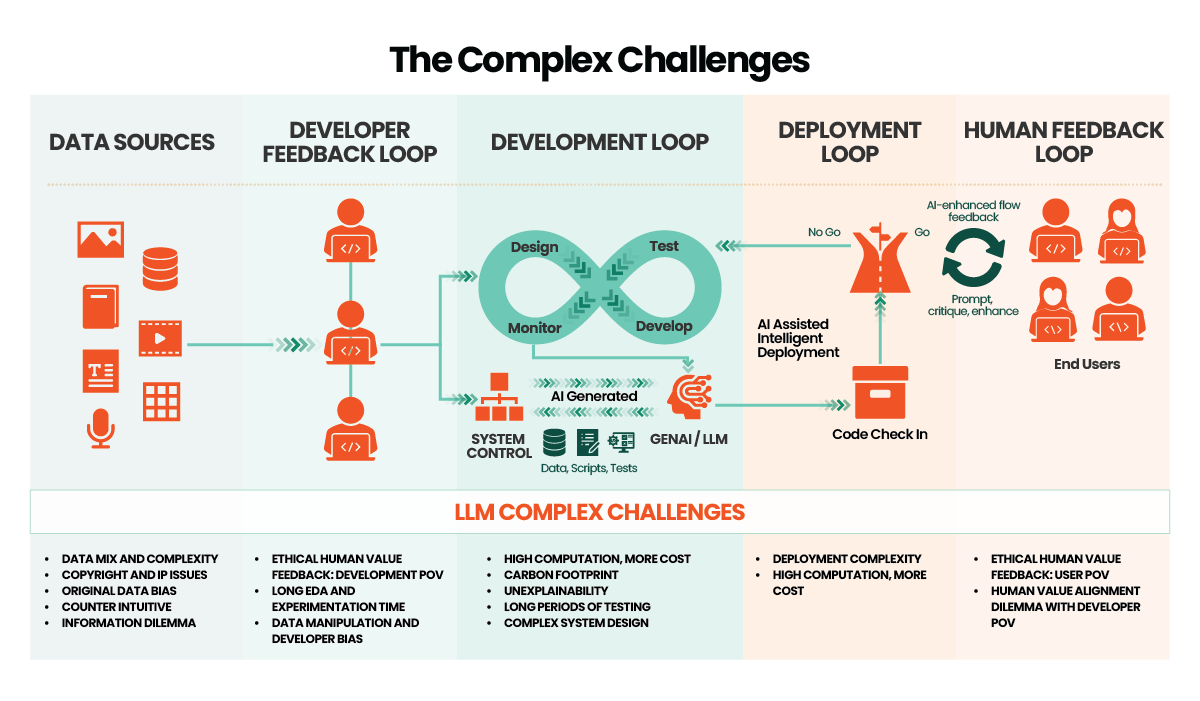
The diagram above demonstrates the end-to-end 10k ft view of the overall lifecycle involved in developing a GenAI/LLM framework and the challenges at each stage. These challenges can broadly be categorized under two topics: -
Technical Challenges at Project Level

Ethical and Legal Considerations of LLMs

Streamlining Workflows with Databricks and MLflow
With the Data Intelligence Platform at the backend and effective conjunction of MLflow with required model support for traditional ML models and LLMs, the potential impact of such a useful structure with Databricks is unimaginable. By marrying Databricks and MLflow, you can adopt a holistic approach to LLM and GenAI use cases. This synergy significantly accelerates competency by offering:
- Reduced Overhead: The integrated platform minimizes the complexity of managing multiple tools and systems, enhancing efficiency and reducing errors.
- Faster Iterations: Streamlined workflows and automation accelerate the model development cycle, allowing you to experiment and innovate more quickly.
- Enhanced Collaboration: Collaboration between data scientists, engineers, and other stakeholders is seamless, leading to improved outcomes and a smoother transition from experimentation to production.
- Model Governance: With the Model Registry and versioning, you can ensure governance and compliance throughout the model lifecycle.
- Scalable Infrastructure: Databricks' scalability ensures you can effortlessly handle large data volumes and compute requirements, a necessity in LLM and GenAI use cases.
Databricks, in collaboration with MLflow, offers a machine-learning platform that addresses the limitations of traditional DS platforms. Databricks is designed to work with most ML/DL libraries, algorithms, deployment tools, or languages, making it highly flexible and customizable. It provides an open interface through REST APIs and simple data formats, allowing users to utilize a variety of tools and share code with ease. MLflow, an integral component of Databricks, enhances the ML development experience by providing comprehensive functionalities. It includes MLflow Tracking, MLflow Projects, and MLflow Models, each serving a specific purpose in the ML lifecycle. Let's explore how MLflow complements Databricks, enhancing competency within data science frameworks and internal tools.
Databricks + => Acceleration + Excellence
Suppose you're a data scientist experimenting with different hyperparameters for your LLM project. Without a robust tracking system, keeping tabs on your experiments and sharing insights with your team could be daunting.
Databricks + MLflow offers:
- Experiment Tracking (MLflow Tracking: Streamlining Experimentation): A streamlined way to log parameters, metrics, and artifacts, ensuring experiment reproducibility and enabling efficient collaboration with colleagues.
- Model Registry (MLflow Models, MLflow Projects): A central hub for versioning and tracking models, making it easy to transition from experimentation to model deployment.
- Model Serving: REST APIs for model deployment, providing a bridge between data science frameworks and internal tools for a smoother transition to production.
- Extensive Integrations: Seamless integration with various machine learning libraries and tools, ensuring compatibility with your existing data science ecosystem.
MLflow and onwards provides LLMOps support as follows, complimenting Databricks:
- Introduction of Mosaic AI as a supported provider for the famous MLflow Deployments for LLMs (formally MLflow AI Gateway).
- Prompt Engineering UI – this new addition offers a suite of tools tailored for efficient prompt development, testing, and evaluation for LLM use cases. Integrated directly into the MLflow Deployments for LLMs, it provides a seamless experience for designing, tracking, and deploying prompt templates.
- Support for parallelized download and upload of artifacts within the Unity Catalog
- Evaluate API has had extensive feature development in this release to support LLM workflows and multiple new evaluation modalities.
- Diverse LLM Providers (Google PaLM 2, AWS Bedrock, AI21 Labs, and HuggingFace TGI) can now be configured and used within the MLflow Deployments for LLMs.
Databricks MLflow provides tools to deploy various model types to diverse platforms. Models supporting the python_function flavor can be deployed to Docker-based REST servers and various cloud platforms as user-defined functions in Apache Spark for batch and streaming inference. MLflow Models can be easily shared and reproduced, allowing seamless integration into various deployment environments.
Real-World Use Cases: Customer LLM and GenAI Case Study
Let's explore a real-world customer case study to highlight the practical application of Databricks and MLflow. This case study will examine how Databricks and MLflow benefited a customer in the LLM (Large Language Model) and GenAI (Generative Artificial Intelligence) domains.
Case Study 1: Leading CPG Giant exploring the GenAI capabilities with Databricks and MLflow
Customer Background
The customer is a leading CPG giant, which looks forward to gaining a competitive edge in the market with anecdotal competitor profiling of their products to better adapt to changing dynamics in the world with respect to raw materials, product trends, and advantageous price point and step/gross margin on their products which gives them cross-functional recommendations to grow their revenue annually by minimum $5 million.
Data Management with Databricks
Classic Medallion Architecture was used to source different datasets (open source, internal lookups, transactional, B2C surveys, etc.), which proved advantageous in their problem scenario for data management and maintenance and adhering to the standards of their company policy.
Experiment Tracking, Reproducibility and Deployment with MLflow
An application that could reverse engineer the prices of their products and give competitive insights on different aspects of the existing market was the main task to better position themselves in the competitive CPG space. The application was built on Databricks, ADF, and ADLS. Across the Bronze, Silver, and Gold Standard layers, data quality trackers were set on the intermediate layers with notifiers to ensure the desired process is followed to maintain consistency in the data and its versions on Delta Lake. The ML Interpolation model and the LLM DeBERTa used for Name Entity Recognition (NER) use case was then monitored through MLflow, where the extensive support and registry of LLM libraries were used to ensure deployment of the product was seamless and cross-functionally available to finance, marketing, operations and R&D teams through PowerBI, which had an intermediate view management of dashboard through Tabular Editor software for seamless dashboard experience.
The monitoring involves several stages: -
- I/O logging - input string and identified entities for NER. For interpolation, it is anecdotal regression, so only output is only stored as the provided input entities from the NER stage are already saved.
- For LLM DeBERTa model
- mF1, categorical cross-entropy loss, Bleu and Rouge benchmarking on the initial finetuning data for DeBERTa LLM used for NER use case
- Drift definition - since it was a multi-class token classification NER, the accuracy benchmarks were taken in accordance with the number of classes the model has to estimate - in our case, we took the benchmark as 78% for a 9-class classification. Drift was defined on both positive and negative improvements to avoid bias.
- Step 3 was made on the logged information - showcased the version of the model, the metrics tracked and monitored in step 2, rules applied on the metrics mentioned in step 2, and then presented a report along with the best model used for the specified NER use case before interpolation.
- For Interpolation model -
- Sklearn models - Linear and Exponential Interpolation (Regression) models were tracked - for simplicity, we only analyzed r2, the number of observations with overshoot and undershoot estimates (absolute errors), % of observations which has the model estimates summing up to 100% across all features.
- Drift definitions based on business logic. - more than 20% of absolute errors and less than 95% of total observations having model estimates on features summing up to 100 is not tolerable by the business.
- Steps 1 and 2 were implemented on logged information, along with model version and scores for each model; the rules applied over these metrics based on business logic based on point number 2.
Results and Benefits
The product was accessible to the teams across the company to gather user feedback, which was promising, and the same was featured in one of their global summits that provided the application to a wider audience.
Case Study 2: Leading Technology Company in NLP and AI-driven applications
Customer Background
The customer is a leading technology company specializing in natural language processing and AI-driven applications. They were looking for a comprehensive solution to streamline their LLM and GenAI development process, allowing them to develop and deploy language models efficiently at scale.
Data Management with Databricks
Databricks provided the customer with a centralized platform for managing their vast amount of data with Lakehouse. The customer leveraged Databricks' large-scale data processing capabilities to handle the volume and variety of data required for LLM and GenAI development. With Databricks' distributed computing framework, the customer was able to process data swiftly and derive meaningful insights.
Experiment Tracking, Reproducibility and Deployment with MLflow
MLflow's Tracking component played a crucial role in the customer's LLM and GenAI development process. The customer utilized MLflow Tracking to log parameters, code versions, metrics, and artifacts during their experiments. This allowed them to track and compare the performance of different language models, making informed decisions based on the results. The web UI provided by MLflow Tracking enabled the customer to visualize and analyze the output of multiple runs, facilitating collaboration among team members and better explainable results using the trained models. The customer leveraged MLflow Projects to ensure the reproducibility of their LLM and GenAI models. By packaging their data science code in MLflow Projects, the customer could easily share and reproduce their work. The standardized format provided by MLflow Projects allowed the customer to specify dependencies and execution instructions, ensuring consistent results across different runs. With MLflow Tracking integrated into their Projects, customers could effortlessly rerun their code and revisit previous experiments. They provided the flexibility to deploy these models to different environments, including Docker-based REST servers and cloud platforms like Azure ML and Amazon SageMaker. With MLflow Models, customers could easily share their models across different teams and integrate them into their production systems.
Results and Benefits
By adopting Databricks and MLflow, the customer achieved significant improvements in their LLM and GenAI development process. The centralized data management capabilities of Databricks allowed them to handle large volumes of data efficiently. MLflow's Tracking component enabled them to track and compare experiments, leading to better decision-making and improved model performance. MLflow Projects ensured reproducibility, making it easier for customers to share and reproduce their work. Finally, MLflow Models facilitated the seamless deployment of their language models to various environments, enhancing their production capabilities.
Conclusion
Databricks, in conjunction with MLflow, offers a powerful solution for accelerating machine learning and AI capabilities. With its open interface and support for various ML libraries, Databricks provides flexibility and customization options that traditional ML platforms lack. MLflow's Tracking, Projects, and Models components streamline the ML lifecycle, enabling efficient data management, experiment tracking, code packaging, and model deployment. Through a real-world customer case study in the LLM and GenAI domains, we have witnessed the practical benefits of Databricks and MLflow. The customer was able to leverage Databricks' data processing capabilities, MLflow's experiment tracking, reproducibility, and model deployment functionalities to enhance their language model development process.
In conclusion, Databricks and MLflow offer a comprehensive and robust solution for companies seeking to accelerate their ML and AI capabilities. Whether managing data, tracking experiments, packaging code, or deploying models, Databricks and MLflow provide the tools and functionalities to streamline the entire ML lifecycle. By embracing these technologies, companies can unlock new possibilities and gain a competitive edge in the ever-evolving field of data science.
Topic Tags





