
UC Managed Tables are Databricks’ flagship table format. In the recently concluded Technical Kickoff (TKO), databricks revealed some of the coolest features of UC Managed table and future roadmap. Below are a few highlights of the same.

What is UC Managed Table?
Databricks supports different types of tables as highlighted below:
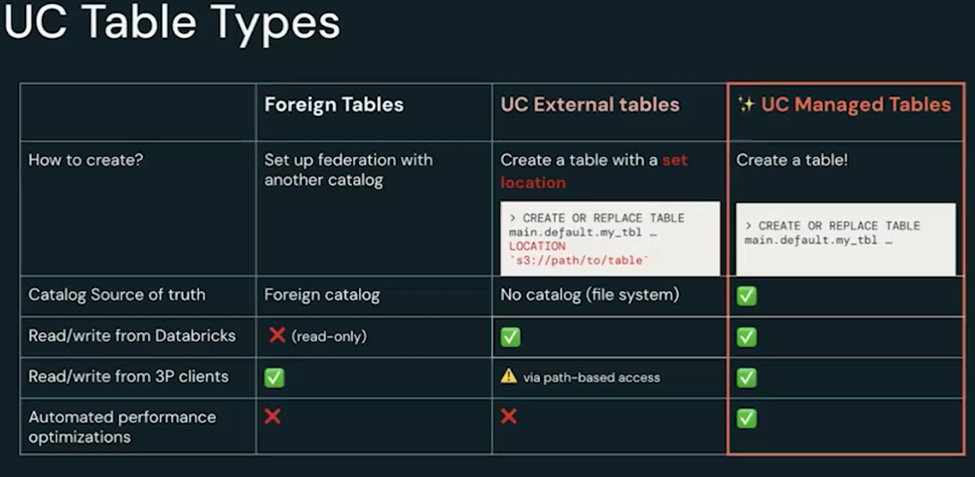
Foreign tables:
- These are tables created in foreign catalogs like in Hive Meta store or Glue and federated with databricks.
- Databricks can’t write to these tables, and they are read only. They can be read or written by Third Party clients though
- They don’t use native databricks benefits like automated performance optimization or faster ETL/ELT
- The only benefit is they can be governed within UC and are discoverable and accessible all within one place
External tables:
- These are created within databricks with a set location
- Its file system-based catalog source of truth so anyone having access to the file system will be able to bypass the governance.
- Databricks can read data from and write data into the table
- But no automated performance optimization
Managed tables:
- Created within databricks without specifying any location
- These are created within the storage locations in customer-managed cloud storage
- Reads and writes are feasible within databricks and from Third Party clients as well
- The biggest benefit it gets is automated performance optimization powered by data intelligence platforms.
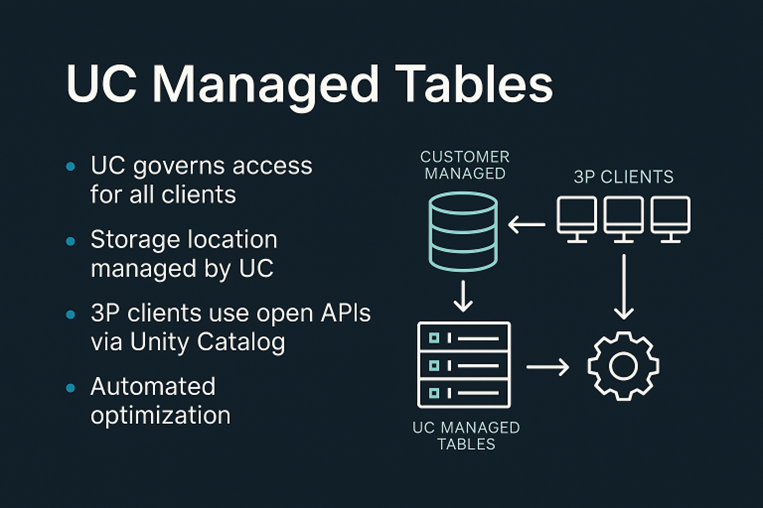
Key Benefits
- UC governs access for all clients
- Storage location is being managed by UC but within Customer managed location.
- Allows reads and writes using Third Party clients using open APIs via single copy of data within Unity Catalog
- Automated optimization Powered by Databricks Data intelligence platform.
- Continuous improvement in Databricks Roadmap.
Deep Dive into Features
- UC Managed tables are stored in Open formats such as Parquet, Delta, Iceberg with metadata on the top
- They can be accessed by different clients via open catalog APIs (UC Rest APIs, Iceberg REST Catalog APIs)
- They can be shared across organizations using Delta Sharing via single copy being maintained within UC.
Delta Sharing in Action
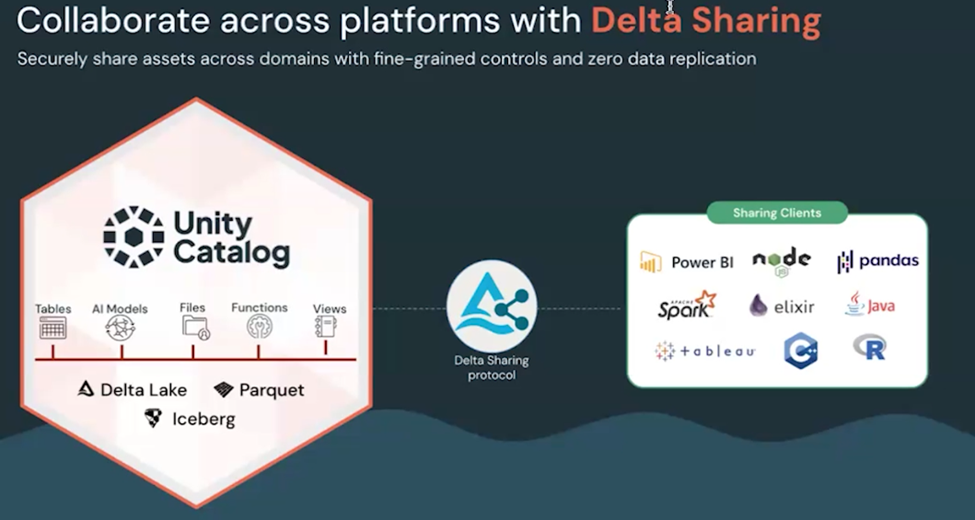
Ref: What is Delta Sharing? — Azure Databricks | Microsoft Learn
With Delta sharing managed table data can be shared with Third Party clients using Secure and reliable Delta Sharing Protocol using single copy being managed and governed by UC.
As shown in the diagram, the objects which can be shared are
- Tables
- AI Models
- Files
- Functions
- Views
Let’s now dive into a simple example of how to create and consume the delta share securely.
Step 1: Enable Delta Sharing (If Not Already Enabled)
In Databricks, enable Delta Sharing in the workspace settings.
Step 2: Create a Delta Share
CREATE SHARE my_data_share;
|
Step 3: Add a Delta Table to the Share
| ALTER SHARE my_data_share ADD TABLE my_catalog.my_schema.my_table; |
Step 4: Grant Access to a Recipient
| CREATE RECIPIENT my_client WITH TOKEN 'client_generated_token'; GRANT SELECT ON SHARE my_data_share TO RECIPIENT my_client; |
Access Delta Share (Python) — Consumer Side — Data Receiver
Install Delta Sharing Client
pip install delta-sharing
|
Read Data from Delta Share (using Pyspark)
| from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName("DeltaSharingConsumer") \ .getOrCreate() df = spark.read.format("deltaSharing") \ .load(profile_file + "#share_name.schema_name.table_name") df.show() |
Open API Integration Example (Product Pricing Comparison Use Case)
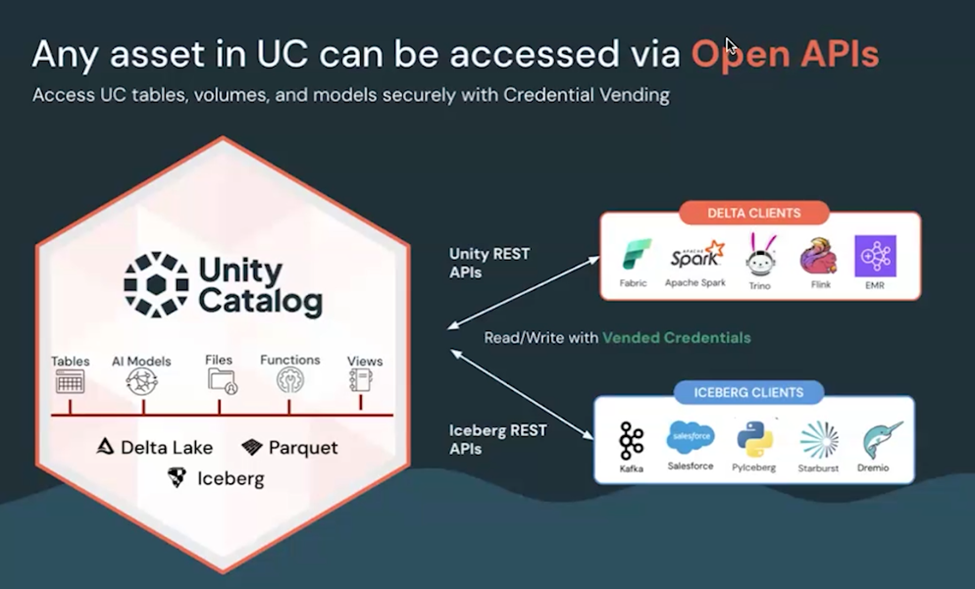
- Delta Lake tables can also be accessed via Unity REST APIs
- Iceberg tables can be accessed using Iceberg REST APIs
- Both of these with single copy of data within UC. Clients authenticate themselves to UC. They use short-lived storage credentials created only for themselves to access only the table which is being shared.
- UC Managed Tables allows third party writes which is one of its kind.
Here are the steps for accessing external data via a generic OpenAPI (REST API)
Install Required Library (if not available)
%pip install requests
|
Use Case: Real-Time Product Pricing with External API Integration
Business Objective:
An e-commerce company wants to:
- Pull real-time competitor pricing data from a third-party pricing intelligence API.
- Combine it with their internal product catalog.
- Recommend competitive pricing using business rules or ML models.
- Push results to dashboards or downstream systems.
Generic OpenAPI Request Example in Databricks: example mock pricing API
GET https://api.pricingintel.com/v1/competitor-price?product_id=12345
|
Returns:
| { "product_id": "12345", "competitor_prices": [ {"store": "Amazon", "price": 99.99}, {"store": "Walmart", "price": 97.49}, {"store": "Target", "price": 98.75} ] } |
Step-by-Step Implementation in Databricks
Step 1: Simulate Internal Product Catalog :
| from pyspark.sql import SparkSession # Sample internal product catalog products = [ {"product_id": "12345", "product_name": "Wireless Mouse", "our_price": 100.00}, {"product_id": "67890", "product_name": "Bluetooth Headphones", "our_price": 150.00}, ] df_products = spark.createDataFrame(products) df_products.display() |
Step 2: Call External Pricing API for Each Product
| import pandas as pd # Convert Spark to Pandas for row-wise API call product_list = df_products.toPandas() pricing_records = [] for _, row in product_list.iterrows(): ext_data = fetch_competitor_prices(row["product_id"]) for competitor in ext_data["competitor_prices"]: pricing_records.append({ "product_id": row["product_id"], "product_name": row["product_name"], "our_price": row["our_price"], "competitor": competitor["store"], "competitor_price": competitor["price"] }) # Create Spark DataFrame from combined results df_pricing = spark.createDataFrame(pd.DataFrame(pricing_records)) df_pricing.display() |
Step 3: Combine External and Internal Data:
| import pandas as pd # Convert Spark to Pandas for row-wise API call product_list = df_products.toPandas() pricing_records = [] for _, row in product_list.iterrows(): ext_data = fetch_competitor_prices(row["product_id"]) for competitor in ext_data["competitor_prices"]: pricing_records.append({ "product_id": row["product_id"], "product_name": row["product_name"], "our_price": row["our_price"], "competitor": competitor["store"], "competitor_price": competitor["price"] }) # Create Spark DataFrame from combined results df_pricing = spark.createDataFrame(pd.DataFrame(pricing_records)) df_pricing.display() |
Step 4: Analyze & Recommend Pricing Strategy
| from pyspark.sql.functions import avg, col # Calculate average competitor price df_avg_price = df_pricing.groupBy("product_id", "product_name", "our_price") \ .agg(avg("competitor_price").alias("avg_competitor_price")) \ .withColumn("recommended_price", col("avg_competitor_price") - 0.50) # Undercut by 50 cents df_avg_price.display() |
Step 5: Push Results to Downstream Dashboard or Table
| # Save results as Delta Table df_avg_price.write.format("delta").mode("overwrite").saveAsTable("recommended_product_pricing") |
Secure API Key Using Databricks Secrets:
API_KEY = dbutils.secrets.get(scope="openapi-secrets", key="pricing-api-key")
|
Performance Optimization (Predictive, Statistics, Liquid Clustering)
Predictive Optimization:

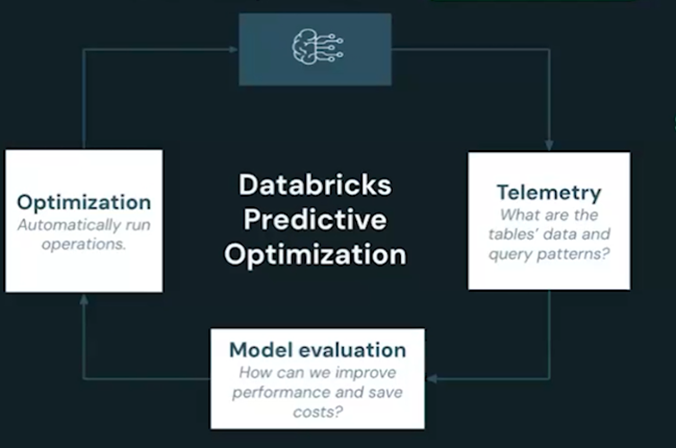
Predictive optimization continuously learns in the backend with the following metrices
- Telemetry — which gives information about what is the table, most popular query, columns used in the query, common predicates being used
- Once telemetry data is collected then model evaluation takes place to improve performance.
- Once model evaluation is done then it runs optimization using serverless infrastructure
Below is a pictorial representation of the entire cycle how predictive optimization works.
Supported optimizations (GA)
- Compaction — to merge the small files into one to reduce scanning
- Clustering for new data which is coming in
- VACUUM to clear the unneeded files from older versions.
Automated Statistics (public preview)
Without Automated Statistics, challenges being faced are
- User must manually run the ANALYZE for query optimization stats
- Users also need to ensure columns which needed data skipping are part of first 32 columns
With automatic statistics
- Query optimization stats are collected and maintained automatically
- And with automated intelligent collection of data stats on required columns, clients should see a 33% improvement in query execution.
Liquid Clustering
Delta Lake liquid clustering replaces table partitioning and ZORDER to simplify data layout decisions and optimize query performance
- Liquid clustering provides flexibility to redefine clustering keys without rewriting existing data, allowing data layout to evolve alongside analytic needs over time
- Liquid clustering applies to both Streaming Tables and Materialized Views.
- It’s widely adopted with 3000+ customers using Liquid clustering monthly
- 170PB+ Data are written into liquid tables monthly
- There are 2PB+largest active liquid tables at present
- It’s available for both managed and external tables
- Much easier to use in UC Managed Table
With external tables there must be explicit mention of columns to be clustered by
Ex: CREATE TABLE TBL1 CLUSTER BY date, product_id
|
Whereas for UC Managed Table, automatic liquid clustering is available
CREATE TABLE TBL1 CLUSTER BY AUTO
|
This will take care of
- Clustering key selection
- Clustering new data on write
- Background clustering
- No need to select which columns to be clustered with as it will be automatically taken care of based on access pattern
Low Latency Queries (GA)
- Cache Delta Metadata for UC manages tables
- Reduce expensive cloud IOs
Migration Path & Myths Debunked
Myth
Customer objection: External tables are more open since I can point directly to the storage path and Managed tables are more closed as their paths are GUIDs
Fact
- Path-based access is insecure since access is given directly to the path bypassing the governance
- Error prone. Since the same path if used by 2 different tables can corrupt the data in case the tables are being loaded at the same time which might corrupt the data.
- On the other hand, UC Managed Mables are completely open in terms of secure access via Delta sharing, Open APIs etc.
- The path for UC Managed Table is being managed within customer storage accounts with only a single copy of data being governed by UC.
Do you want to know how to migrate External tables to UC Managed Table to get all indigenous benefits?
Databricks has a new capability in Private Preview which allows seamless migration from external to Managed table with minimal to zero downtime
Run a single alter command as below
ALTER TABLE catalog.schema.external_table SET MANAGED
|
Characteristics:
- No data movement or duplication
- Path-based code from DBR continues to work just that it will be automatically redirected to UC metadata
- Minimal downtime (<1min) for creation of delta log creation in UC managed location

AUTHOR - FOLLOW
Shakti Prasad Mohapatra
Senior Solutions Architect
Next Topic
Azure Databricks Lakeflow: The Ultimate Guide to Effortless Data Orchestration
Next Topic





