
Do you want to automate complex data workflows like a pro? Azure Databricks Lakeflow is here to make your life easier. This guide will show you how Lakeflow is changing the data orchestration game and why it should be part of your data engineering toolkit.
What is Azure Databricks Lakeflow?
Azure Databricks Lakeflow is a next-gen data orchestration tool within the Azure Databricks ecosystem. It offers a low-code, visual interface for designing, scheduling, and monitoring complex data pipelines. Think of it as the traffic controller of your data workflows, ensuring everything flows smoothly, whether it’s batch processing or real-time streaming.
How Azure Databricks Lakeflow Works
Azure Databricks Lakeflow works by integrating seamlessly with Azure Databricks, Delta Lake, and other Azure services. Its architecture includes:
- Automated Workflows: Drag-and-drop design tools to create data workflows.
- Dependency Handling: Ensures tasks run in the correct sequence.
- Delta Live Tables (DLT) Integration: Automates data processing and reliability.
Source: Azure Databricks Documentation
Components of Databricks Lakeflow
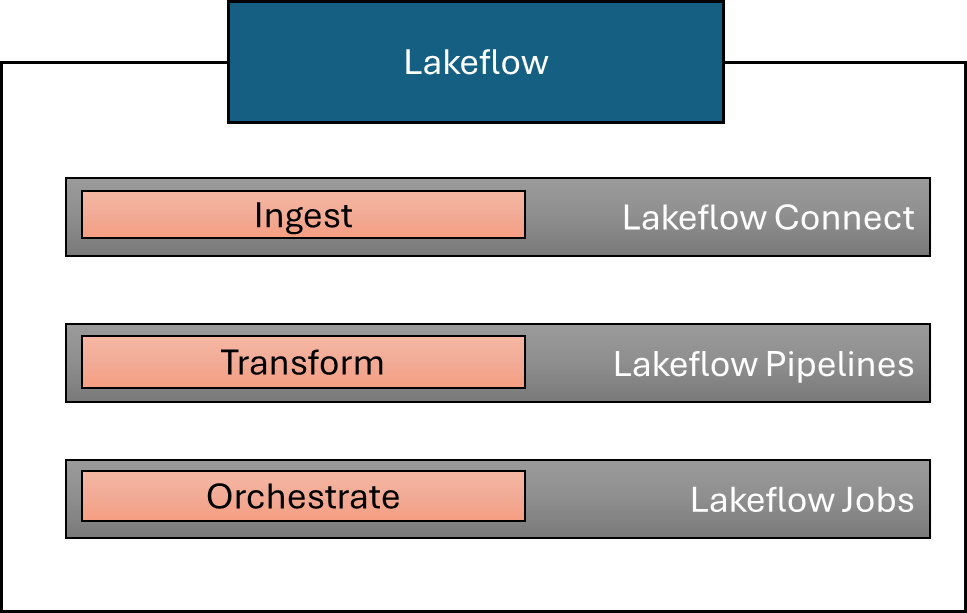
Benefits of Using Azure Databricks Lakeflow
Why should you care about Lakeflow? Here are some benefits:
- Scalability: Handles big data workloads with ease.
- Reliability: Built-in monitoring and alerting for error-free pipelines.
- Simplified Data Pipelines: Low-code approach reduces complexity.
- Cost-Effectiveness: Optimized for resource usage, saving both time and money.
How CDC is handled with Traditional ETL logic without Declarative ETL for streaming data with micro-batches:
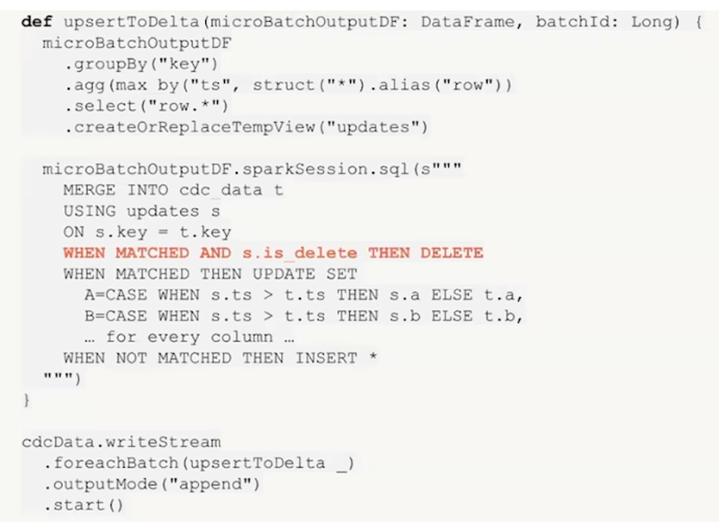
23+ Lines of Code handling updates in same microbatch, out of order updates, Deletes etc.
How CDC is handled with declarative ETL using Lakeflow:

5 Lines of Code
Source: Databricks TKO
Key Features of Azure Databricks Lakeflow
Lakeflow isn’t just a fancy tool — it packs some real power. Here’s what you get:
- Low-Code Interface: Design complex workflows without deep coding expertise.
- Real-Time Monitoring: Stay informed with alerts and automated retries.
- Delta Live Tables Integration: Enhanced data reliability and tracking.
- Workflow Scheduling: Automate data ingestion, transformation, and analysis.
Lakeflow Dashboard:
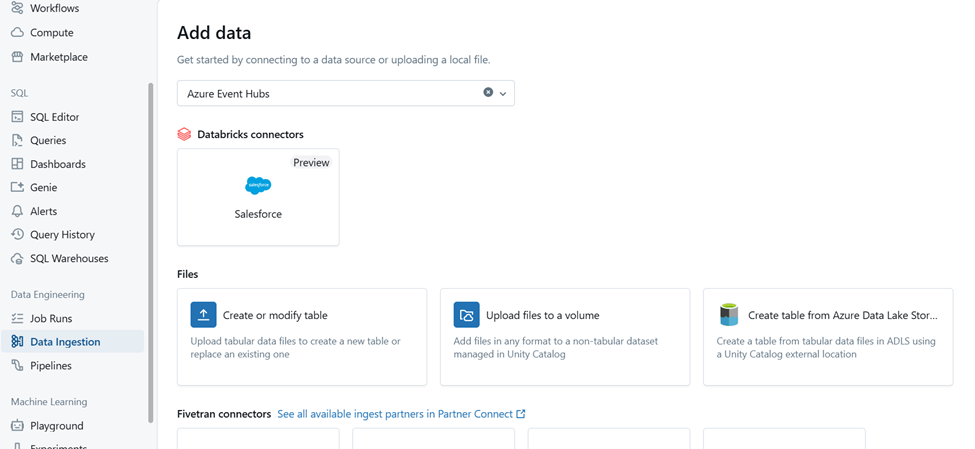
There are hundreds of connectors available directly from Databricks or via Partners like fivetran.
Below is a sample connector to ingest data from Salesforce.
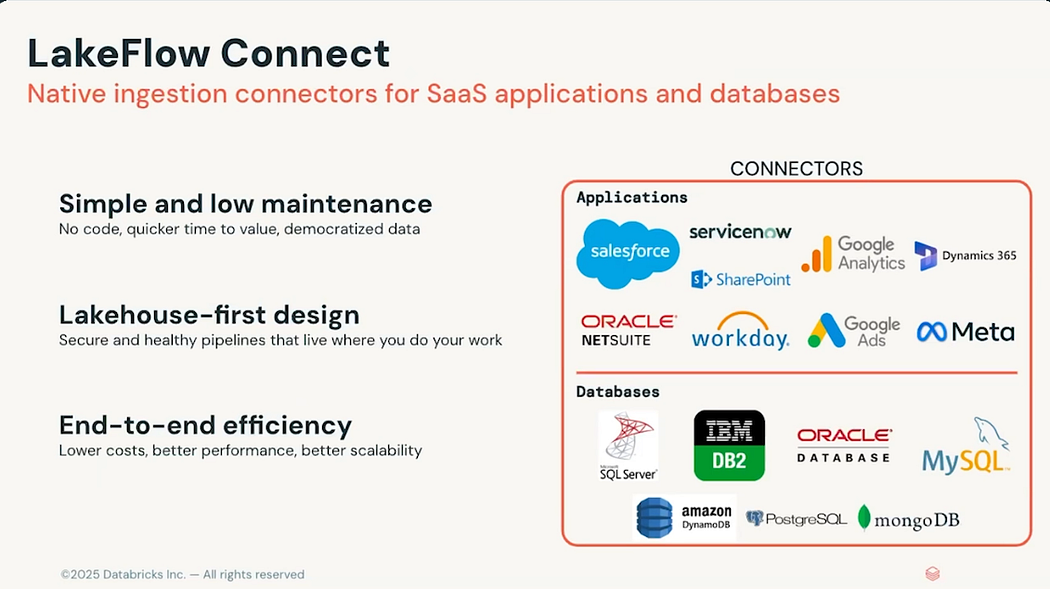
Databricks Lakeflow Connect is a new tool designed to simplify data ingestion from external systems. It features built-in connectors that seamlessly integrate with popular databases like SQL Server and business applications such as Salesforce or Google Analytics.
It leverages efficient incremental reads and writes to make data ingestion faster, scalable, and more cost-efficient while your data remains fresh for downstream consumption.
It is also native to the Data Intelligence Platform, so it offers both serverless computing and Unity Catalog governance. Ultimately, this means organizations can spend less time moving their data and more time to get actual values from it. It includes many data sources (some in preview):
- Salesforce
- ServiceNow
- Google Analytics 4
- SharePoint
- PostgreSQL
- SQL Server on-premises
- Workday
Step by Step process to create an ingestion Pipeline using Lakeflow connect
Step 1: Click New to create a new data ingestion Pipeline.
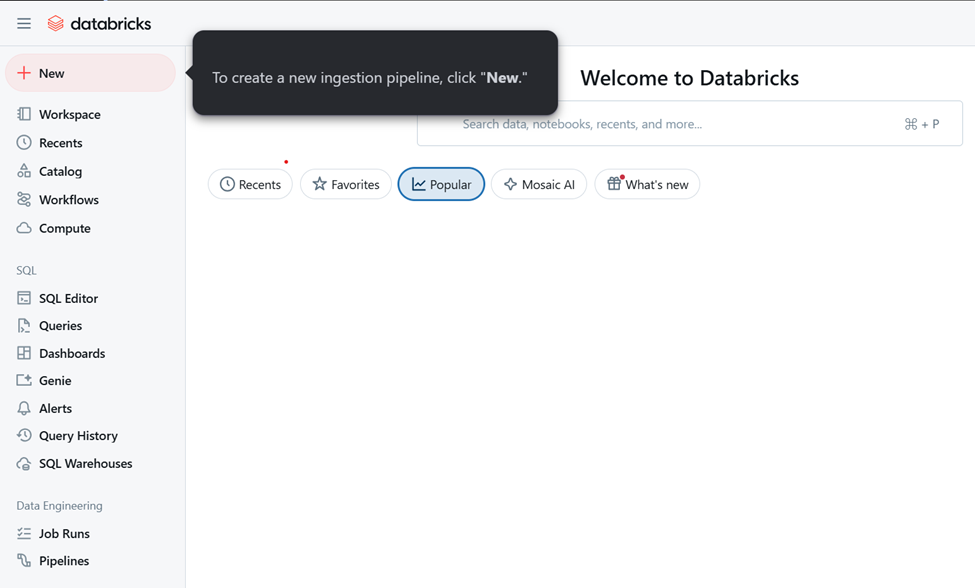
Step 2: Click on Add or Upload data.

Step 3: Choose connector to upload data from. Currently databricks offers 3 connectors in Public Preview. But more will be added sooner.
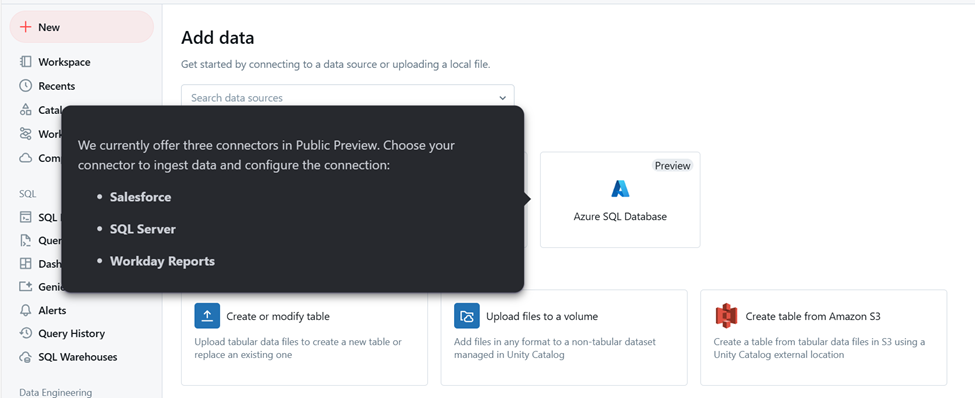
Note: Most recent update: SQL Server is also in Public Preview
Step 4: Here we have chosen SQL server as the source to ingest data from.
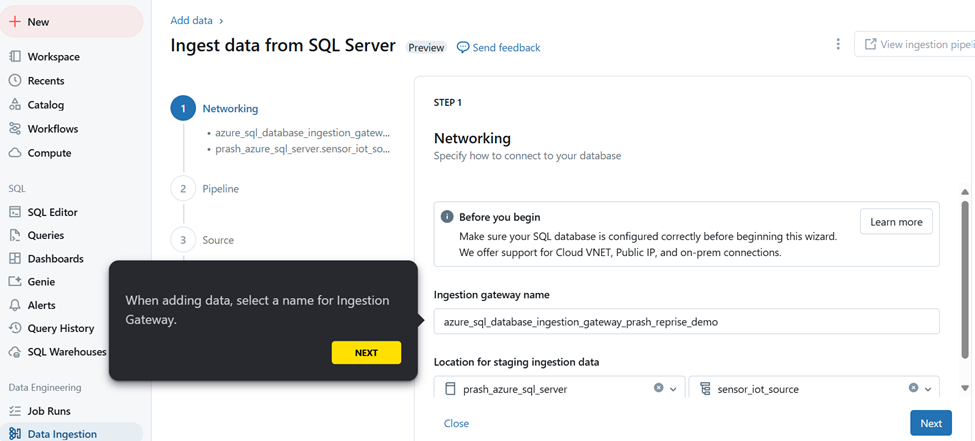
Step 5: Choose a location for staging the ingested data.
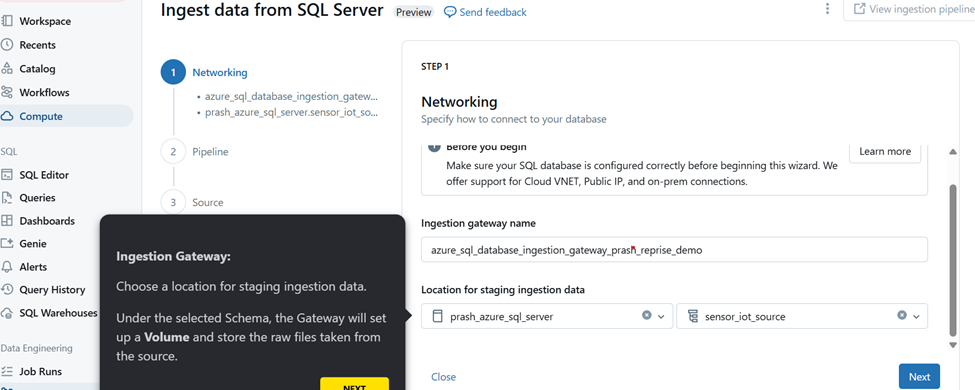
Step 6: Now once the staging location is set click on next to create the pipeline.
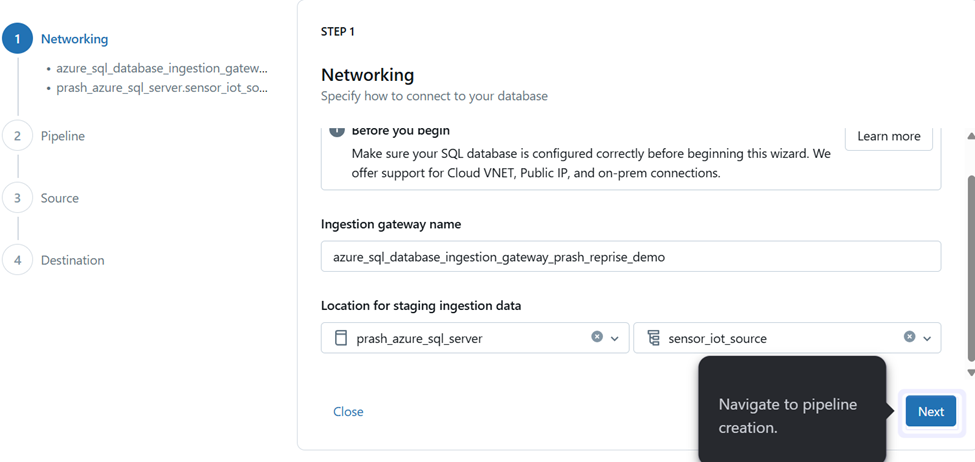
Step 7: Select the connection that was created before
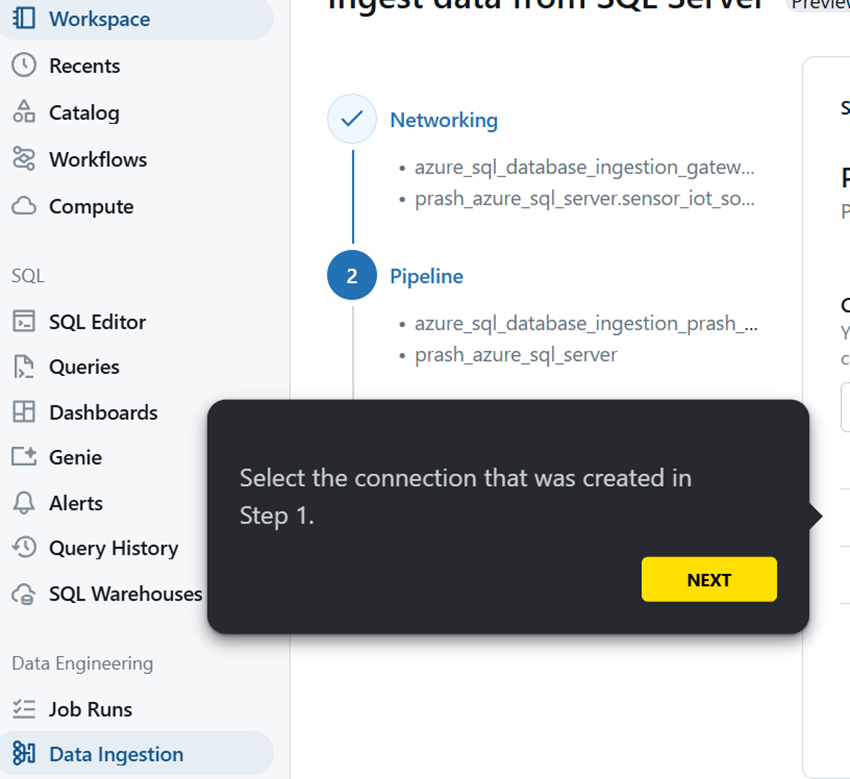
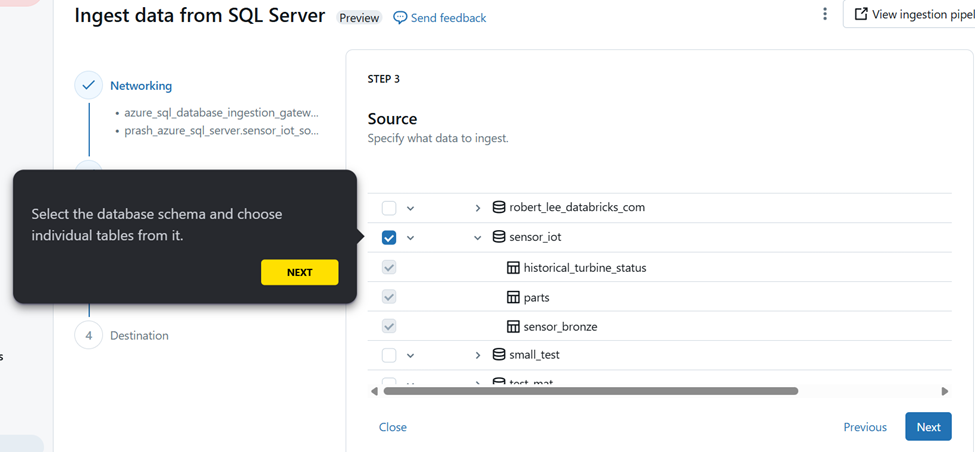
Step 8: Choose the tables form source to ingest data from
Step 9: Choose the Target schema in catalog to write the data to.

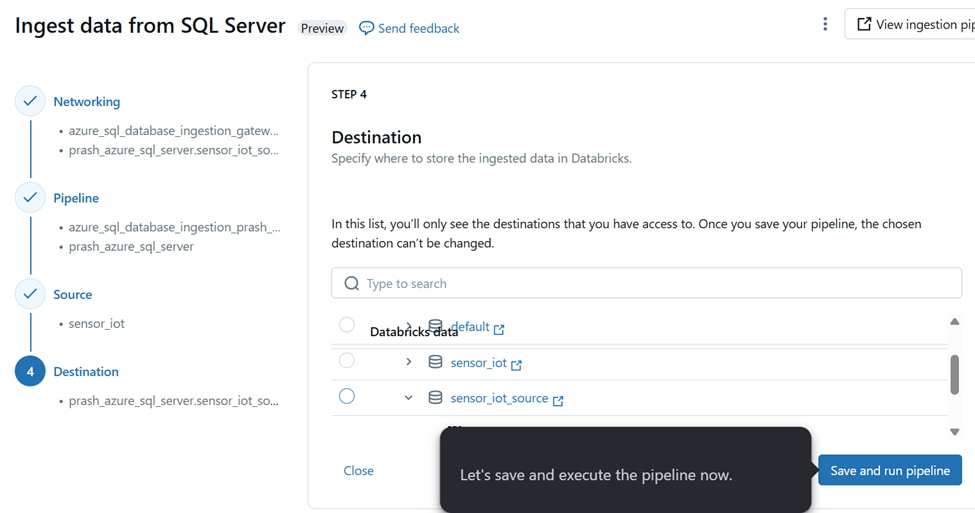
Once the pipeline is executed status will show completed.

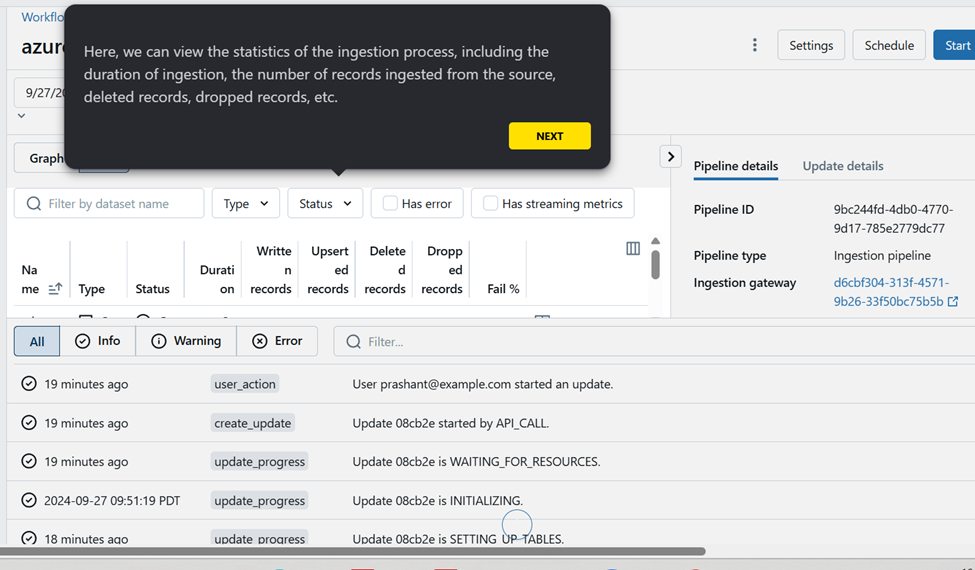
Developer can view the statistics for ingestion process as stated below.
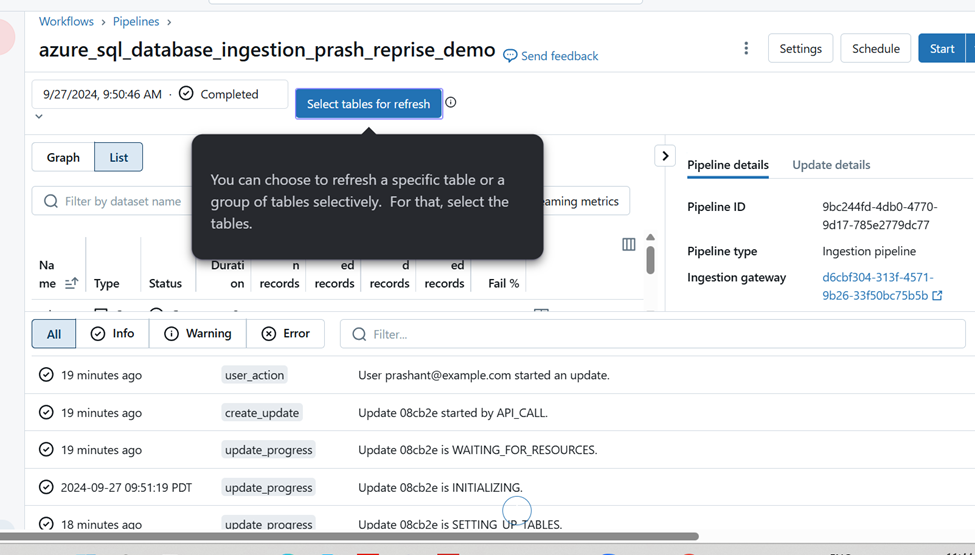
Setup CDC for all tables within the Pipeline.
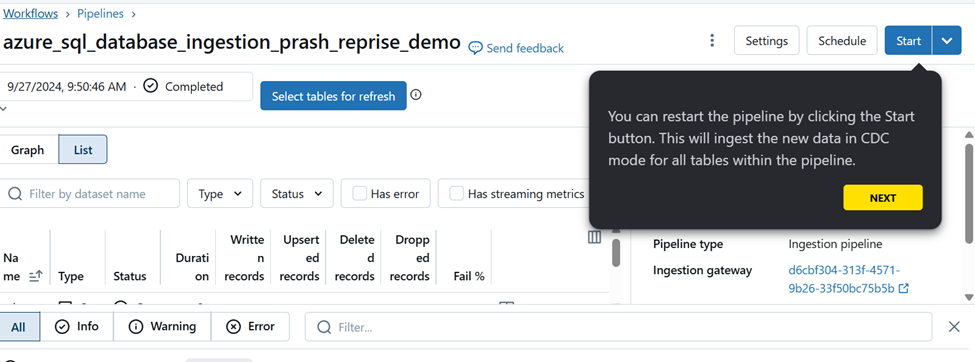
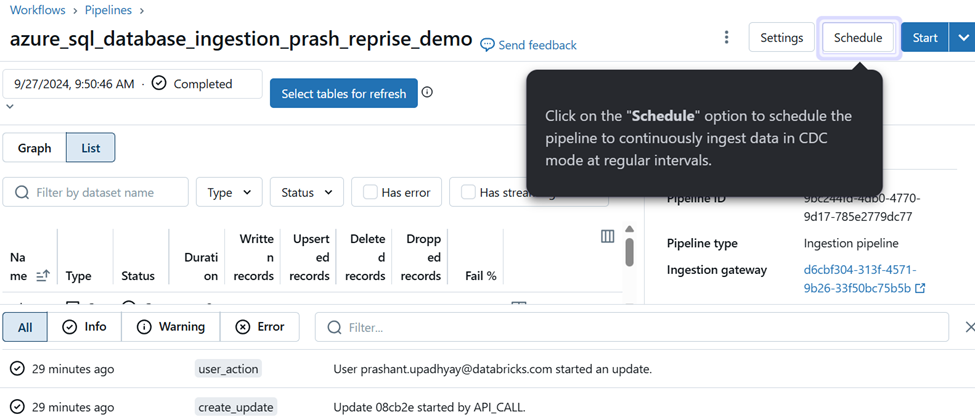
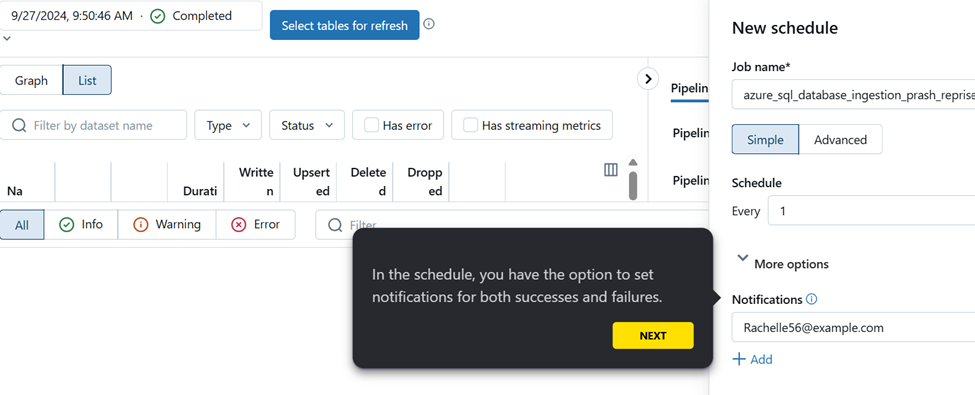
To modify the permission for the pipeline click on settings and then permission settings.

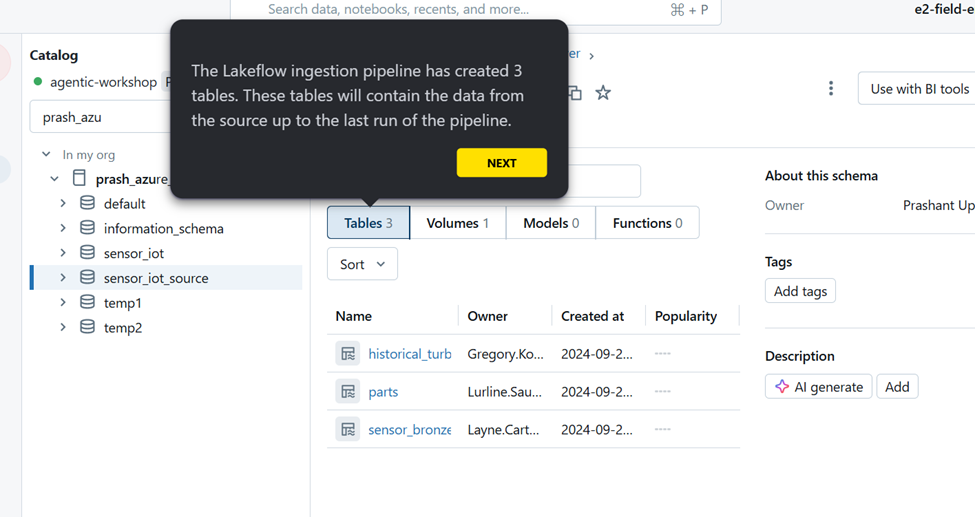
Check the target catalog to check which tables got loaded.
Setting Up Azure Databricks Lakeflow
Ready to get started? Here’s what you need:
- Azure Subscription: Get access to Azure services.
- Azure Databricks Workspace: Create and configure your workspace.
- Delta Live Tables Knowledge: While not mandatory, it’s beneficial.
Once set up, you can design, deploy, and monitor your workflows right from the Azure Databricks UI.
Data Pipeline Orchestration with Lakeflow
Azure Databricks Lakeflow makes orchestrating data pipelines easier than ever.
- Creating Pipelines: Design workflows using the low-code editor.
- Scheduling Tasks: Automate the frequency of data processing.
- Handling Failures: Define recovery mechanisms for enhanced reliability.
Azure Databricks Lakeflow vs. Traditional Data Pipelines
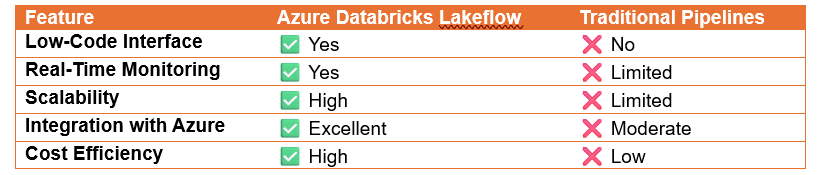
TCO Comparison: LakeFlow vs. Traditional ETL Tools

How Databricks LakeFlow stands out over traditional data engineering tools.
- Unified Platform for Ingestion, Transformation, and Orchestration
Unlike traditional ETL tools that often require separate platforms for ingestion, transformation, and orchestration, LakeFlow integrates all three processes into a single unified platform. This integration minimizes complexity, reduces tool sprawl, and enhances data governance. This is in my opinion best as it removes the hassle of choosing and maintaining different platforms for each process.
- Declarative Pipeline Framework
LakeFlow Pipelines use the Delta Live Tables (DLT) framework, which allows users to write transformations declaratively using SQL and Python. Databricks handles orchestration, incremental processing, and infrastructure management. This simplified approach improves efficiency and productivity compared to traditional ETL tools that require extensive manual configuration. Declarative framework also gives you lineage of data movement which helps in debugging and tracking the source-target mapping and transformation the data gone thru. It comes with inbuilt data quality checks which prevents complex codes to perform the same with traditional ETL.
- Serverless Compute
By providing serverless compute options, LakeFlow reduces operational overhead, as users don’t need to manage infrastructure directly. It automatically scales resources based on workload requirements, which is a significant improvement over traditional tools where provisioning and scaling resources can be complex and costly.
- Real-Time Processing with Lower Latencies
Traditional ETL systems often rely on batch processing, which can introduce delays. With LakeFlow’s Real-Time Mode for Apache Spark, users can process data with low latencies, enabling real-time analytics and decision-making.
- End-to-End Monitoring and Observability
LakeFlow Jobs offer enhanced orchestration and monitoring capabilities, including built-in alerting, logging, and lineage tracking. This makes troubleshooting and optimization much more efficient than with fragmented monitoring tools commonly used with traditional platforms.
- Better Cost Efficiency
Incremental processing, serverless compute, and efficient resource utilization lead to reduced infrastructure costs. Traditional tools often require provisioning for peak loads, resulting in resource wastage during idle periods.
- Seamless Integration with Azure Ecosystem
As part of Azure Databricks, LakeFlow integrates well with Azure’s security, identity, and storage solutions (like Azure AD, Azure Blob Storage, and Azure Synapse Analytics). This provides better security, governance, and compliance than standalone traditional tools.
- Scalability
LakeFlow’s architecture supports massive data volumes with high throughput and low latency, whereas traditional tools might struggle to scale efficiently as data sizes grow.
- Comprehensive Governance with Unity Catalog
Through Unity Catalog, LakeFlow provides centralized data governance, lineage tracking, and access controls. Traditional tools often require separate governance layers or additional tooling to achieve the same level of compliance.
- Flexible Language Support
Unlike some legacy tools that only support SQL or proprietary languages, LakeFlow supports Python, SQL, and various machine learning libraries, enhancing its usability across data engineering and data science tasks.
How Partners & Ecosystem Players Can Extend LakeFlow’s Capabilities
LakeFlow is not just a standalone solution — it thrives in a broader data ecosystem. Partners and third-party providers can extend LakeFlow’s capabilities in several ways:
- Custom Connectors & APIs: Solution providers can develop custom ingestion connectors to integrate with proprietary systems like SAP, legacy mainframes, and industry-specific applications. Databricks provides a general compute platform. As a result, you can create your own ingestion connectors using any programming language supported by Databricks, like Python or Java. You can also import and leverage popular open-source connector libraries like data load tool, Airbyte, and Debezium.
- Data Quality & Observability Enhancements: Tools like Great Expectations, Monte Carlo Data, Alation, or Collibra can integrate with LakeFlow to provide advanced data quality and governance.
- ML & AI Extensions: Machine learning vendors can extend LakeFlow pipelines to support ML model training & inference directly within the workflow, enabling AI-powered automation.
- BI & Visualization Integrations: LakeFlow works seamlessly with Tableau, Power BI, and Looker, allowing real-time analytics from LakeFlow pipelines.
This open ecosystem approach ensures that businesses can customize and enhance their LakeFlow deployments based on their unique requirements.
Best Practices for Using Lakeflow
- Optimize Workflows: Regularly fine-tune your pipelines for better performance.
- Monitor Costs: Keep track of resource usage to avoid unnecessary spending.
- Maintain Data Quality: Regular validation ensures accuracy.
Challenges of Using Azure Databricks Lakeflow
Every tool has its limitations. Here’s what you should know:
- Learning Curve: New users might find advanced features overwhelming.
- Cost Management: High workloads can be expensive if not optimized.
- Complex Workflows: Designing highly intricate pipelines may require advanced skills.
Databricks makes it easy to overcome these learning curves with extensive training and certification options:
- Databricks Academy: Free & paid courses on LakeFlow, Delta Live Tables, and Spark
- LakeFlow Documentation: Step-by-step guides for ingestion, pipelines, and orchestration
- Community & Partner Support: A thriving Databricks user community and certified partners to assist with implementation
- Hands-on Labs & Notebooks: Pre-built notebooks to experiment with LakeFlow features in a sandbox environment
By leveraging these resources, data teams can quickly upskill and accelerate adoption without disruption to ongoing operations.
Conclusion The Future of Data Engineering
Azure Databricks LakeFlow represents a significant leap forward in data engineering, offering an all-in-one solution that addresses the limitations of traditional ETL tools. From unified data management to real-time processing and serverless computing, LakeFlow empowers data teams to build scalable, efficient, and resilient data pipelines.
By choosing LakeFlow, businesses can accelerate their data transformation journey, reduce operational costs, and gain faster insights — all while leveraging the powerful Azure cloud ecosystem.

AUTHOR - FOLLOW
Shakti Prasad Mohapatra
Senior Solutions Architect
Next Topic
How to Implement Databricks Asset Bundle and Make a Seamless Deployment Process
Next Topic





