
In the last post, we onboard an AI agent to was able to record the traces effortlessly. That is just one aspect of the AI agent ecosystem. The next step is to evaluate the responses to make sure that the model is giving quality output. LLMs are equipped with general knowledge but it might lack domain knowledge that requires more complex decision making, like chess playing. With a little experimentation, we know that LLMs are not good at playing chess yet. As mentioned previously, there is a long history of using chess as a research topic from IBM’s Deep Blue to DeepMind’s AlphaZero. While we can conclude machine learning models or rule-based engines, like Stockfish, already excels at finding patterns, when it comes to explaining why they make these decisions, it is still a bit of a mystery.
Human in the loop
When an LLM does not have enough domain knowledge, we can do a fine-tuning to enhance its knowledge. However, without human input, we might not be able to know where it goes wrong. By bringing in human for reviewing a pre-production quality app, we can achieve the following:
- Determine if we want to do a RAG (providing documents for clarifications) or fine-tuning (changing the way the LLM is thinking)
- Provide a diverse set of reviews on where the problems might be
- Humans, especially domain experts, have a more in depth understanding of the topic hence can provide more high-quality input
What’s the next move?
Let’s first look at response from DeepSeek. Because the thinking was too long, I have left out the complete thinking but jumped directly into conclusion.
Mid-game between DeepSeek and Stockfish where DeepSeek has the advantage of being White.
PGN: 1. e4 c5 2. e5 Nc6 3. Nf3 d6 4. Nd4 cxd4 5. e6 Bxe6 6. Qh5 g6 7. Qg5
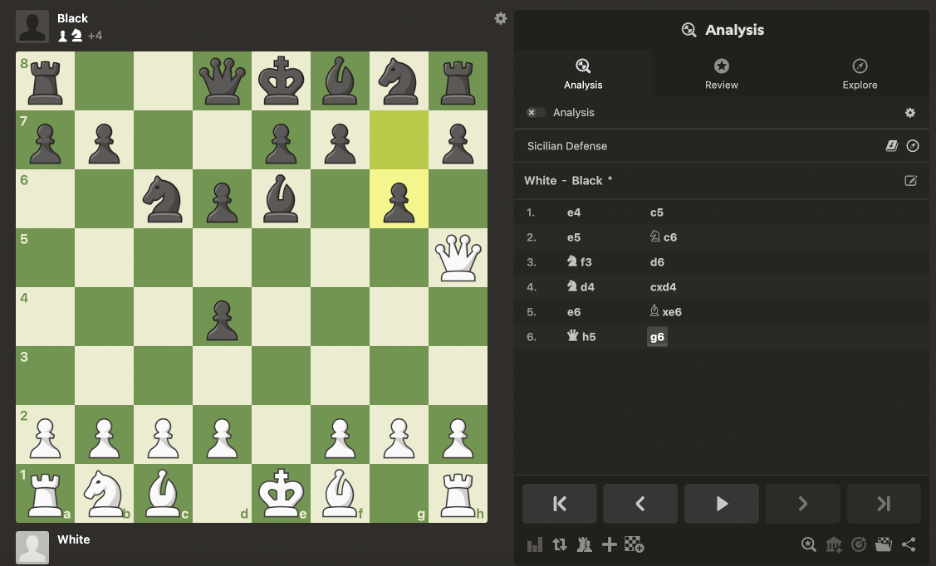
Partial Response from DeepSeek
"So, overall, capturing the pawn on e7 with the queen, delivering check, seems like a good next move. It gains material and forces the Black king to move, which will help White in the endgame towards checkmate or at least a decisive advantage.
</think>
The best move is to capture the pawn on e7 with the queen, forcing the Black king to move and setting up for further attacks."
Human feedback
Despite the long thinking, it seems like AI is being aggressive and not consider the pros and cons of this move. It can be a risky move if it were a business decision. From human perspective, we need to balance the trade-off between aggressive vs advantage. An example of human feedback can look like below:
"It’s a bad move because it loses a piece for nothing. It doesn’t threaten anything, so there’s no follow up. The only reason it’s not completely losing is because white is slightly behind in development, so black has to be a little bit careful. If black is careless, white can just take the free piece and black is behind in development and down a pawn. So black has to play carefully, and this move doesn’t help."
From the above response, we know that the game is not in a great shape, and we shouldn’t count on pure luck, and we need to admit that we are not winning, which sometimes it seems to be an LLM not being good at. And the Queen, the most powerful piece in the game, should retreat to safety. That’s one situation where human needs to analyze whether it stills make sense to charge forward and find a solution regardless (hallucinations) or try to come up with a different plan.
Databricks Review App to the rescue
Now that we have a prototype of an agent, and deployed it into pre-prod. We need to evaluate the performance and fix quality issues before deploying it to production. For example, we don’t want to deploy a decision-making agent into production that would otherwise be making risky decisions for an organization.
Below is high level overview of the workflow:

As seen from the above diagram, collecting the evaluation set spans through the entire lifecycle of the process, it is a critical task. We need to have a way to systematically collect these feedbacks and the best place to collect them is to deploy an app where the agent is. Below Databricks allows you to use one line to deploy a review app.
| from databricks.agents import deploy from mlflow.utils import databricks_utils as du deployment = deploy(model_fqn, uc_model_info.version) |
In the above code, model_fqn is essentially the unity catalog model name, which can be the following:
https://docs.databricks.com/aws/en/generative-ai/agent-framework/ai-agents
- An LLM, like a foundation model API. In our case we try to have a foundation model playing chess with Stockfish

- LLMs + tool chains. A typical example is an RAG application, we can give the LLM some additional information to refine its knowledge. We can leverage langchain or langgraph and log the chain or alternatively we can log a python file directly. For example:
from mlflow
|

- An autonomous AI agent. When empowering LLMs with tools, it will try to figure out what tool to call and when. In our case, we can give an LLM a stockfish API so it will know how to play chess well.

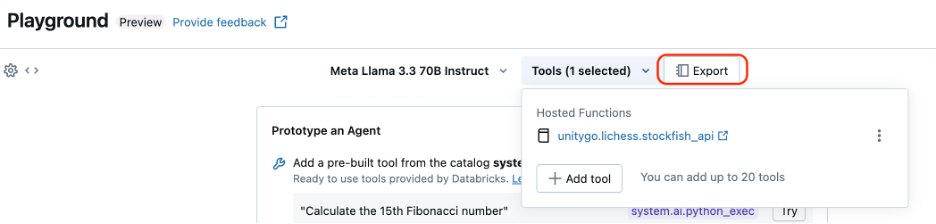
Databricks provides an easy interface for us to generate the code required for this type of agent, which can be found in the Playground with the Export button.
Data labeling session
With the review app setup, we can collect more and more traces, but we need human experts to review the results in order to decide the next step.
The below code demonstrates how to use the review app to start a labeling session:
| from databricks.agents import review_app my_exps = ["xxxx", "yyyy"] my_review_app = review_app.get_review_app() my_review_app.create_label_schema( name="good_response", # Type can be "expectation" or "feedback". type="feedback", title="Is this a good response?", input=review_app.label_schemas.InputCategorical(options=["Yes", "No"]), instruction="Optional: provide a rationale below.", enable_comment=True, overwrite=True ) my_session = my_review_app.create_labeling_session( name="collect_facts", assigned_users=[], # If not provided, only the user running this notebook will be granted access # Built-in labeling schemas: EXPECTED_FACTS, GUIDELINES, EXPECTED_RESPONSE label_schemas=[review_app.label_schemas.GUIDELINES,review_app.label_schemas.EXPECTED_FACTS, "good_response"], ) traces_from_the_updated_model = mlflow.search_traces(experiment_ids=my_exps, filter_string = "status = 'OK'") my_session.add_traces(traces_from_the_updated_model) # Share with the SME. print("Review App URL:", my_review_app.url) print("Labeling session URL: ", my_session.url) |
It takes a few minutes to deploy but we will see the review app as follow:

Conclusion
In this post, we discussed some very important reasons why we need human to review the agent that we deploy. There is a very compelling reason why we can’t just trust an LLM agent without thoroughly testing with human experts. We have collected all the valuable traces from the last post but we will continue to collect them, regardless the app is in development, in pre-production or in production.
Without a doubt Databricks is a very good platform to develop and test an agent, but having a pre-built user-interface for us to iterate and improve on the feedback is a breaking new experience that’d simplify the development lifecycle a lot. Allowing organizations to focus on deploying high-quality agents to production.

AUTHOR - FOLLOW
Jason Yip
Director of Data and AI, Tredence Inc.





