
Databricks is known for its performance in data processing. However, many developers are not leveraging the power of Databricks for machine learning or the tools the company developed for experiment tracking and model deployment. Recently, Databricks has revamped its interface to better organize the different parts of the tooling

While most use the Data Science & Engineering features, Machine Learning is also now a big part of Databricks. In 2021, Databricks was named a Leader in the Gartner Magic Quadrant for Data Science and Machine Learning Platforms.
The best way to start with Machine Learning is to leverage the Glass Box AutoML provided out of the box from Databricks.
What is the Glass Box Approach to Automated Machine Learning?
Machine learning is a highly iterative task. Data scientists spend a lot of time trying out different algorithms and doing hyperparameter tuning to find the best-performing model. But these repetitive tasks can be automated by using AutoML.
Unfortunately, most of the platforms out there, for example, Azure Machine Learning, while capable of doing the job of picking the best model, are a black box because the code to train the model is not provided, and it is not easy to replicate the best performing model and do the further enhancement. Databricks' Glass Box approach provided all the source code that generated all the models, not just the best performing but all the models evaluated, allowing data scientists to customize the models with the source code provided.
Machine Learning Operations Lifecycle
A typical MLOps lifecycle has the following stages:
- Data Prep
- Model building
- Model deployment
We can conveniently use Databricks to do everything. Furthermore, to harness Spark's distributed nature, we can use libraries like Horovord and Petastorm to scale out the model training.

The best way to learn how to build a model within Databricks is, of course, through Databricks. That makes the Glass Box AutoML an attractive approach to start with.
Even though AutoML does not address all the machine learning problems, it does offer a framework for solving several common ML issues. This further saves data scientists' time in gaining insights into the quality of the models that can be built with the dataset.
Databricks AutoML supports the following ML problem types:
- Classification
Classification allows you to assign each observation to one of a discrete set of classes, such as good credit risk or bad credit risk
- Regression
Regression allows you to predict a continuous numeric value for each observation, such as annual income - Forecasting
Time-series forecast allows you to predict a future value based on a hierarchy, for example, a future store sale in each city of each state in the US
We will demonstrate AutoML using a classification problem on a flight dataset, which can be found in Kaggle. Based on historical flight data, this problem predicts whether a flight will be delayed or canceled. Of course, the real reason for a flight delay or cancellation can be attributed to many factors beyond the flight itself, like weather or staff shortage. This exercise by no means demonstrates how to build a state-of-the-art on-time flight predictor. Instead, it simply uses a dataset to illustrate the workflow of MLOps using Databricks.
Predicting Flight Delays with Databricks' AutoML
Prep Data
Prepare Data
First of all, we need to upload the data to Databricks. This can be done easily with JDBC or simply by uploading the CSV file, and then we can create tables from there.
The Create New Table wizard found under the Data tab can be leveraged for uploading data and then creating a table using UI or notebook.

Exploratory Data Analysis (EDA)
Databricks has integrated Panadas Profiling for EDA. Pandas Profiling is an open-source library that pre-compute some statistics that data scientists would typically want to know and save these into properly formatted HTML. Once we hook up our data in the AutoML interface, it will also generate EDA reports from Pandas Profiling.

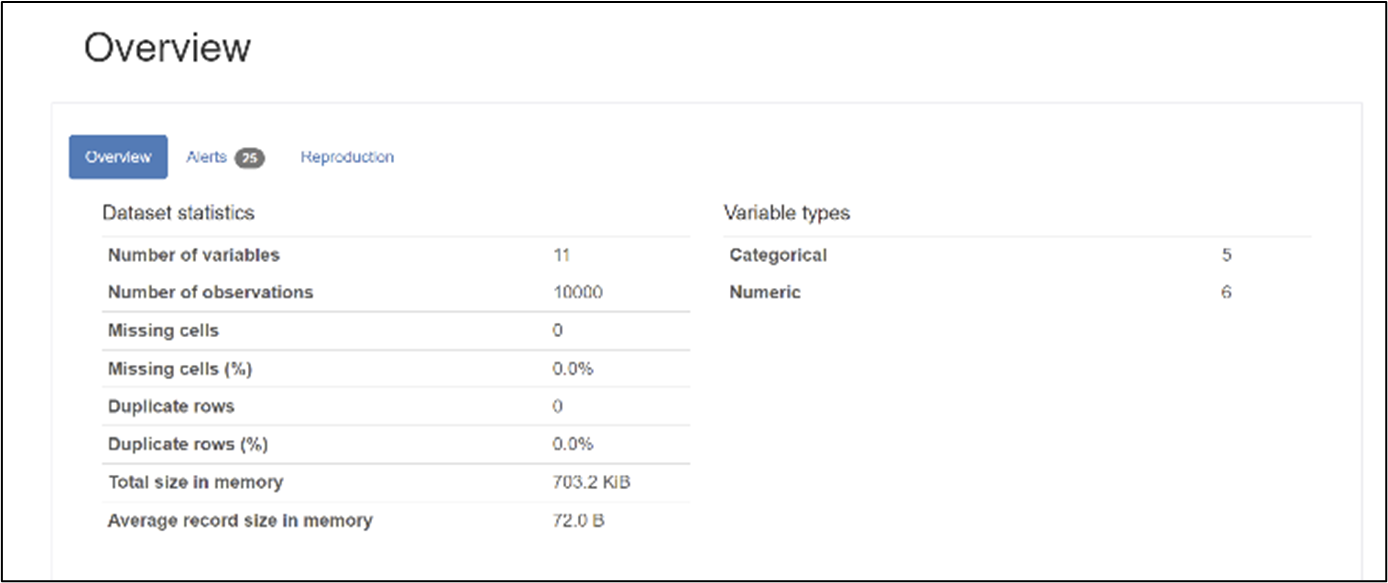
By clicking on the data exploration notebook, we can also look at how Databricks is leveraging Panda‘s profiling to do EDA.
Feature Engineering
In most cases, we need to transform raw data into something useful that the model can use for better predictions. For example, in our flight delay example, we can compute the percentage of delayed flights by airport or by the airline. We can then save these into the feature store so other team members can reuse them and understand how these were built. For more information about how to use the feature store, please refer to this tutorial from Databricks.

Build Model
Model Training
After features engineering, the next most time-consuming task is to train and tune your model and sometimes carefully select the algorithm or the architecture of your model so it can achieve the best accuracy. With Databricks' Auto ML, we can seamlessly select the data from the Data tab and allow it to perform hundreds of selections automatically, saving data scientists hours of effort to build these from scratch.
As seen below, the interface only contains a few dropdowns and is fully integrated with the feature tables and the delta tables created and persisted in the Data tab. The next thing is to choose a prediction target. Finally, we can also choose how to handle imputation, a process of handling nulls in the dataset. Auto ML will then handle the rest of the model selection, tuning hyperparameters, and presenting the results with the notebook.
The below documentation shows how many different algorithms Databricks will try in each ML problem type. For classification, there are five models we can expect:
- Scikit-learn models: Decision trees, Random forests, Logistic regression
- XGBoost
- LightGBM

Databricks' AutoML interface
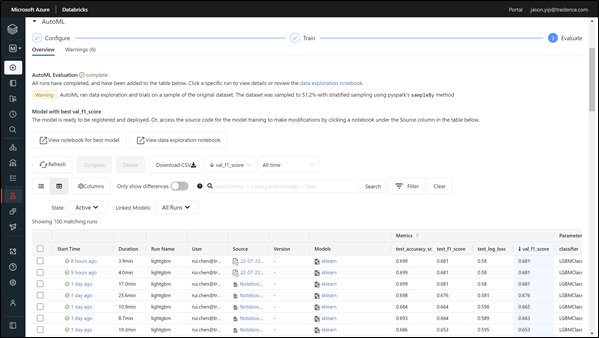
AutoML will automatically select the top 100 most relevant results
Validation
Before we deploy the model to production, we need to validate the model with test data set. We would usually split the data into a training set and a test set with ratios like 70/30 split or 80/20 split. We can do random split, or splitting based on a business key, aka stratified split. Some more advanced approaches can include training/validation/test split with the validation used for hyperparameters tuningn these scenarios, we can split the data into 60/20/20 for train/val/test. AutoML uses the latter approach for splitting.
In Databricks Runtime 10.1 ML and above, we can specify a time column for splitting for classification and regression problems. This provides flexibility when some problems are based on chronological order.
Deploy Model
Deployment/Inference
Auto ML will automatically register the artifacts into the Model store. The model will follow the ML Flow standard.
Inside the model tab, we can also deploy, aka serve the model, for external consumption. This can also be done with one click. This will generate a REST API endpoint, so the model can easily be accessed through any external tools.

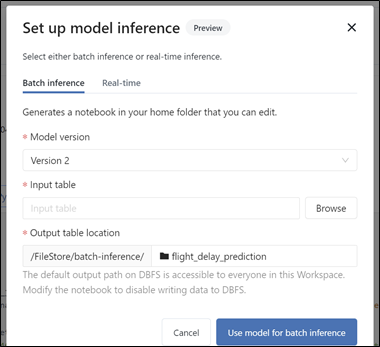
For model inference, we have a choice between batch inference and real-time in. We can easily select a table to produce inference results and output the results to a new table using the UI.
For real-time inference, we can use the python code provided and connect with a real-time streaming pipeline using DLT (Delta Live Tables). This is an advanced option.
Monitoring
ML Models are not built-once and run forever. So, we do need to retrain our models. The real question is, when do we need to retrain? Some people decide to train the model daily, but a more proactive approach is to detect data drift and trigger a retrain when it happens. Simply saying, Data drift is the change in input data that causes the model performance to degrade over time. This can be caused by missing data in the pipeline, for example. While Databricks does not provide an out-of-the-box drift detector, we can easily leverage the SQL workspace to build a drift monitoring dashboard and trigger ‘retrain’ when drift happens.

Details of this process is out of scope of this article, but a hands-on lab by Databricks can be found here.
Conclusion:
"Databricks’ Glass Box approach to machine learning will be the key that unlocks your data for insights"
While the concept of MLOps is not new, organizations normally need to spend weeks taking an ML model to production because they need to code up the model and then tune it. In between, they also need to work closely with data engineers and ML engineers to ensure they are getting the latest data and deploying the latest model for testing.
When using Databricks’ Glass Box Auto ML approach along with other toolsets like feature store, data scientists can now speed up their process of getting to a baseline model, which is an important milestone in evaluating the effectiveness of the input data. Then they can leverage the code generated to build a production model while seamlessly collaborating with data engineers and ML engineers using the intuitive interfaces.
Databricks has recently taken Machine Learning operations to the next level. While many tools out there can manage the MLOps lifecycle, Databricks is the only platform that allows a team of data experts to work together seamlessly without jumping through multiple hoops of toolsets. There is no doubt that Databricks is a leader in both Data Science and Machine Learning.

AUTHOR - FOLLOW
Jason Yip
Director of Data and AI, Tredence Inc.
Topic Tags





